概要
Clouderaが公開しているVMイメージを利用して、CDH4を動かしてみる。VMを立ち上げればすぐにHadoopが試せる便利な一品。
本例ではOSはMint13を使用してる。VMなんで他のディストリでもWindowsでも動きはほとんど変わらないはず。
@CretedDate 2013/10/13
@Versions CDH4.3
@Versions Mint13
イメージのダウンロード
まずはClouderaのダウンロードサイトへ行って、VirtualBox用のイメージを落としてくる。Cloudera QuickStart VMというヤツ。
https://www.cloudera.com/content/support/en/downloads.html
ちなみにファイルサイズはかなり大きい。自分が落とした時は2.4GBだった。ダウンロード完了までにけっこうかかるので、将棋でもするか本でも読みながら待つ。8六歩、同歩、8五銀 …… 2七銀。
落としたら解凍する。
このVMに関する説明書きには、こんな風に書いてある。
This VM contains a single-node Apache Hadoop cluster along with everything you need to get started with Hadoop, including Cloudera Manager and example data, queries, and scripts.
訳 : このVMにはシングルノードのHadoopが用意されてて、Hadoopを始めるのに必要なモノが入ってるよ。Cloudera Managerとか、サンプルデータとか、クエリとか、スクリプトも入ってるよ。
Hadoopはインストールとか何かと面倒だけど、こうやってVMで用意しとけば楽でいいね。
VirtualBoxを用意
イメージはVMWare、KVM、VirtualBoxが用意されている。今回はVirtualBoxを利用する。Oracleの持ち物ではあるけどGPLのフリーなソフトウェア。
https://www.virtualbox.org/
Windowsなら上記サイトからインストーラをダウンロードする。うちはMint使ってるのでapt-getで入れた。
$ sudo apt-get install virtualbox
インストールできたらVirtualBoxを立ち上げて、ファイル → 仮想アプライアンスのインポートから、落としてきたイメージを開く。
CPUやメモリは自機の性能と相談して設定し、インポートを実行。完了すると下記のように何か出来上がってる。
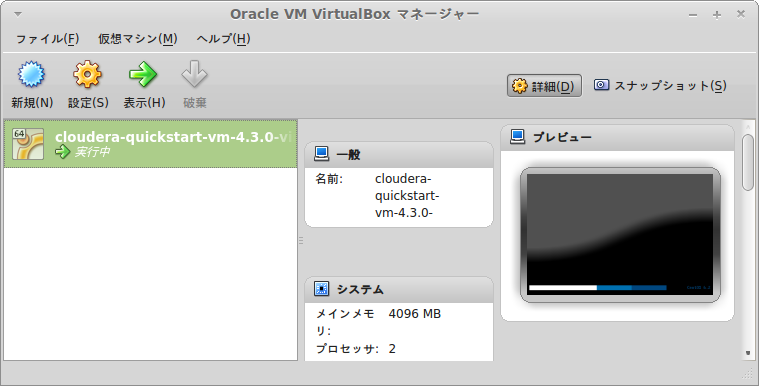
立ち上げる前に右側に出てくるネットワークで、ブリッジアダプター(ホストOSと同じネットワークを使用する)を設定しておく。これでDHCPなら勝手に立ち上がったVMに対してIPアドレスが割り振られるはず。
あとは対象を右クリック → 起動で当該イメージ(CentOS)が立ち上がる。
VirtualBoxの簡易な説明
初めて操作する際に必要になりそうな情報をまとめておく。
まず、ショートカットで使われるHostキーは、Linuxなら右Ctrlキーがたいてい割り当てられている。
Host+Fでフルスクリーンモードになる。Host+IでマウスがVirtualBox内に捕獲される。Host+Lでシームレスモードという、ホストコンピュータのウィンドウに混ざるモードになる。ブラウザから使うのがメインになるので、Firefoxだけ立ち上げてシームレスモードで操作するのありかもしれない。
先程、ネットワークをブリッジアダプターに設定しておいたので、IPアドレスはルータから振られているはず。このIPでホストコンピュータからsshで接続することもできる。ログインする際のユーザ名/パスワードの初期値はcloudera/cloudera。
Alt+PrintScreenがそのままだと効かない。VirtualBox内でAlt+Tabを押してもVM内で遷移する。この状態はHostキーを押すと一時的に解除される。右下に出ている右Ctrlが緑の時はVM内に捕獲されている状態。グレーになっていればAlt+PrintScreenやAlt+Tabがホストコンピュータ側で動作する。
デフォルトだとクリップボードの共有はできない。「デバイス」から「Guest Additionのインストール」を選び、Guest Additionをインストールする。あとは「設定」の「一般」から「クリップボードの共有」で「双方向」を選ぶ。設定はすぐには有効にならないようで、一度VMをShutdownして再度立ち上げると有効になっていた。これでテキストのクリップボードは共有できる。
終了する時はメニューの「仮想マシン」から「仮想マシンの状態を保存」を選んで終了すれば、次に起動する時に前回終了時そのままに起動できる。
VM上に入っているものを眺めてみる
Clouderaのイメージを起動すると、まずブラウザが立ち上がる。ここでHueやCloudera ManagerからHadoopを操作できる。
キーボードが英語配列になってるので、viを使う時に思ったような挙動にならなくて困る。ということで、CentOS上の、System → Preferences → Keyboard → Layoutsから、日本のレイアウトを選んでおく。
VMのCentOSは英語設定。日本語フォントとかは入ってないので、たとえばそのままブラウザで日本語ページを見ると文字化けする。コンソールから下記手順で日本語化は可能。
$ sudo yum groupinstall "Japanese Support"
$ sudo vi /etc/sysconfig/i18n
// LANGを下記に変更する
LANG="ja_JP.UTF-8"
これで再起動すると日本語化される。
Cloudera Managerを覗いてみると、既にHDFS、Hive、Impala、Zookeeper、Solr、Fluemeなど、Clouderaの主要製品が用意されていることがわかる。
デスクトップにはEclipseも用意されている。開くとtrainingという名前のプロジェクトが入っていて、MapReduceのJobのスタブコードが入っている。StubTestというクラスがいて、これはMRUnitを使ったUnitテストの準備をしている。
HueからHiveを動かしてみる
Firefoxを立ち上げると、ブックマークツールバーにHueやCloudera Managerへのリンクが付いている。
HueもCloudera Managerも、ユーザ名/パスワードはadmin/adminで入れる。下記のようにHiveやImpalaなどがすぐ使えるようになっている。
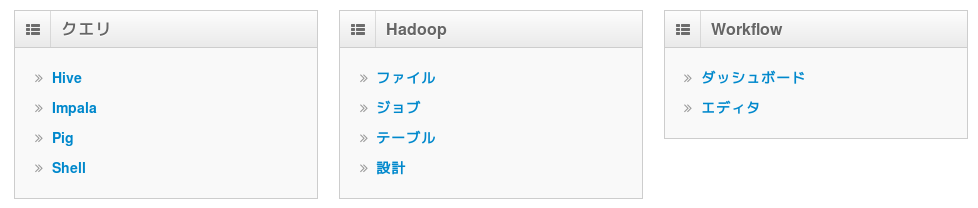
初期状態ではHDFSにもHiveにもImpalaにもデータが入ってないので、用意されているサンプルデータを入れてあげないといけない。
$HOME/datasets配下にサンプルデータが用意されている。たとえば下記のシェルを実行すれば、Hiveにデータが取り込まれる。
$ ~/datasets/zipcode-setup.sh
上記シェルの中を覗くと、median_income_by_zipcode_census_2000.zipというファイルを解凍して、HiveのテーブルにLOADしている。
HiveのCREATE文は下記のような感じ。
CREATE TABLE ZIPCODE_INCOMES (id STRING, zip STRING, description1 STRING, description2 STRING, income int)
シェルを実行後にHueにログインしてHiveに入り、下記のようなクエリを実行すると、ちゃんと結果が取れる。
select * from zipcode_incomes where zip='59101';
この辺の説明は下記URLに詳しい。
http://blog.cloudera.com/blog/2013/06/quickstart-vm-now-with-real-time-big-data/
Impalaも動かしてみる
初期状態ではImpalaは眠っているらしい。起こす為にFirefoxからブックマークツールバーのCloudera Managerを開いてログインする。下記のような画面が表示されるので、Impalaのアクションから開始を実行する。
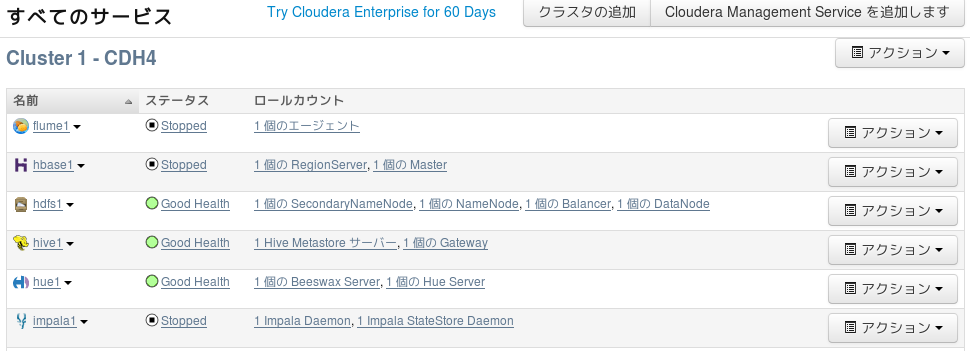
無事開始したらコンソールから下記のコマンドを実行する。
$ impala-shell -q refresh
これでImpalaさんも使えるようになった。試しにHueからHiveで投げたのと同じクエリを実行してみる。
select * from zipcode_incomes where zip='59101';
下馬評通り、Hiveと比べるとかなり素早く結果が返ってくる。実処理にかかる時間はこの程度のデータ量では大きくは変わらないはずなので、前準備の差がそのまま出ていると思われる。
HDFSにデータを置いてみる
HDFS上にデータを置いてHueから見てみる。以下のコマンドでとりあえずHDFSに適当なCSVデータを置く。
$ cd /tmp
$ unzip /home/cloudera/datasets/median_income_by_zipcode_census_2000.zip
$ hadoop fs -mkdir /user/cloudera/example
$ hadoop fs -put DEC_00_SF3_P077_with_ann_noheader.csv /user/cloudera/example/
Hueにログインし、Hadoop→ファイルから、ファイルを置いた/user/cloudera/example配下を見てみる。ちゃんとデータが置いてあって、中身を見るとファイルの1ブロック目が出力される。
以前はこういうの確認する時ってコマンド使ってたんだけど、随分と便利になったものだ。
EclipseからMapReduceしてみる
Eclipseを立ち上げると必要なjarがclasspathに追加された状態のプロジェクトが存在する。Maven等は利用していない一般的なJavaプロジェクト。用意されているソースにはYARNではなくMapReduceのソースが記述されている。
読み込まれているjarは/usr/lib/hadoop配下のものが使われているので、Hadoop上のjarとEclipse上のjarは一致したものになる。
MapperとReducerには何も記述されていないけど、とりあえず何もしないJobでも実行させようということで、StubDriverのTODO implementsの下あたりに下記のコードを追加。
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
あとはEclipseのFile→Exportからjarを出力する。
さっきHDFSに置いたcsvファイルに対してジョブを実行してみる。jarの名前はexample.jarとする。
$ hadoop jar example.jar StubDriver /user/cloudera/example /user/cloudera/example_out
HueのHadoop→ファイルから当該ディレクトリを見てみると、ちゃんとexample_outというディレクトリが出力されている。まぁ、何もしてないので結果は0byteのファイルが出ているだけだけど。
感想
Cloudera QuickStart VMを使うとかなり手軽にHadoopを体験できることがわかった。こりゃ便利だ。複数人で開発する時はこのVMを元に開発環境用のスナップショットを作っておいて、開発環境を揃えるという使い方もできそう。
VMにIPアドレスが割り振られていれば、そこに対してホストコンピュータ側からブラウザでアクセスもできるしSSHでも入れる。VirtualBox上では特に操作せずに、ただのサーバという意識で利用することもありそう。
一点、Hadoop系の処理はストレージに対して負荷をかけることが多く、それが元でホストコンピュータの動きが悪くなることがある。CPUやメモリは割り振り方次第でなんとでもなるけど、ストレージはボトルネックになりやすいので、HDDを2台積んで片方をVMに割り振っておくと負荷を感じることが減るかもしれない。