概要
Mapperがローカルで集約処理を行うin-mapper combiningのサンプルコードをScalaで書いてみる。
@Date 2012/04/04
@Versions CDH3, Scala2.9.1
in-mapper combining
in-mapper combiningは子像本に載ってるMapReduceの手法。Mapperで集約処理を行なうことで、Reducerに渡すデータを削減する。
例えば一般的なWordCountのMapperが以下のような文書を解析したとする。
山 山 川 川 海 海 海 滝
この塲合、下記のような情報がReducerに渡されることになる。
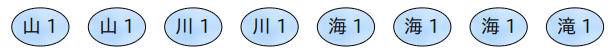
Mapper内で集約してしまえば、Reducerに渡すデータは下記のように少ない情報量で済む。
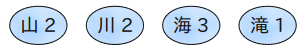
Combinerを使った場合もReducerに渡るデータは似たようなものになるけど、中間データの出力がない分、速度はin-mapper combiningの方が速い。
コード例1
in-mapper combiningを使ってWordCountしてみる。
Mapperはsetup → map → cleanupの順でメソッドが呼ばれる。setupで初期化して、mapで出力する情報を詰めて、cleanupで集計結果を出力してみる。
class Mapper1 extends SMapper[LongWritable, Text, Text, LongWritable] {
var countMap: collection.mutable.Map[String, Long] = null
// setupで初期化
override def setup( context: Context ) {
countMap = collection.mutable.Map[String, Long]()
}
// map処理でmapに詰める(名前が被ってて嫌だ)
override def map(key: LongWritable, value: Text, context: Context) {
for (word <- value.toString.split("\\s"))
countMap += word -> (countMap.getOrElse(word, 0L) + 1L)
}
// cleanupでmapが詰めた情報を出力
override def cleanup(context: Context) {
for ((word, count) <- countMap)
context.write(new Text(word), new LongWritable(value))
countMap.clear()
}
}
上のサンプルはSMapperというクラスを継承してるけど、これはContetとかを自動で定義する自作のクラス。下記みたいな。
trait SMapper[KEY_IN, VAL_IN, KEY_OUT, VAL_OUT]
extends Mapper[KEY_IN, VAL_IN, KEY_OUT, VAL_OUT] with ImplicitConversions {
type Context = Mapper[KEY_IN, VAL_IN, KEY_OUT, VAL_OUT]#Context
}
サンプルコードではやってないけど、気分的にcontext.writeするKeyやValueはインスタンスを使い回す方が好き。context.nextKeyValue()の時もインスタンス使い回されてるみたいだし。
コード例2
runメソッド(setupやmapを呼び出す元のメソッド。継承可能)を直接書いた方が、わかりやすいし楽な気もする。
class Mapper2 extends SMapper[LongWritable, Text, Text, LongWritable] {
// runメソッドに書いてみる
override def run(context: Context) {
// mapを呼ばずに自前でループして値を詰める
var map = collection.mutable.Map[String, Long]()
while (context.nextKeyValue()) {
for (word <- context.getCurrentValue().toString.split("\\s"))
map += word -> (map.getOrElse(word, 0L) + 1L)
}
// 出力
for ((word, count) <- map)
context.write(new Text(word), new LongWritable(count))
}
}
気を付ける点
メモリ上に集計結果を持つので、集計するデータの内容によってはOutOfMemoryが起きて処理が落ちる場合がある。実際に上のサンプルコードはMapperのXmxがデフォルト(200M)だと落ちた。
単純なWordCountでもこうなるということは、それ以上のKeyが出現するような(例えば隣り合う単語のパターンをカウントするとか)データを扱う場合は、Xmxを上げるだけでは対処できない。
あと、集計してもあまりデータ量が圧縮されないような処理では、やっても意味がない。
実行時間
試しにWikipediaの英語版のabstract.xmlの中からabstract要素のところだけ切り取ったファイルを作り、WordCountしてみる。
こいつのenwiki-latest-abstract.xml
ファイルのサイズは443M。JobTracker1台、TaskTracker2台の構成で実行。mapred.child.java.optsに-Xmx512Mを指定。Reducerは1つ。
という条件で実行してみたところ、実行時間はin-mapper combining使用時は72秒、combinerを使って集計した場合は130秒、Reducerのみで集計した場合は197秒という実行時間になった。
また、Jobの詳細のところで見れるFILE_BYTES_WRITTEN(mapperやreducerが出力したファイル)の合計は、in-mapper combiningが330MB、combiner利用時が719MBに対して、Reducerのみで集計した場合は4.73GBと桁が1つ違う数字になった。
メモリ不足対策
速度は上がるものの、上記のような簡易なカウントの例でも、設定によってはOutOfMemoryが起きる。ので、使うときはいつもメモリを気にしないといけない。
Keyが小さくValueが大きくなるようなデータであれば、指定容量を超えたらValueをストレージに逃してくれるようなキャッシュライブラリを利用すれば良さそうだけど、Keyだけでメモリの容量を超えるようなケースは下手にストレージに吐き出してもパフォーマンスが心配。
比較的楽な対処法として、メモリが満たんになるたびにキャシュの中身を出力してしまうことが考えられる。例えば下記はfreeMemoryが残り10MBを割ったら一端出力を実行する例。
class Mapper1 extends SMapper[LongWritable, Text, Text, LongWritable] {
var countMap: collection.mutable.Map[String, Long] = null
override def setup( context: Context ) {
countMap = collection.mutable.Map[String, Long]()
}
override def map( key: LongWritable, value: Text, context: Context ) {
for ( word <- value.toString.split( "\\s" ) )
countMap += word -> ( countMap.getOrElse( word, 0L ) + 1L )
// freeMemoryが10MB割ったらcleanupを呼ぶ
if ( Runtime.getRuntime().freeMemory() < 10 * 1024 * 1024 ) cleanup( context )
}
// 出力
override def cleanup( context: Context ) {
for ( ( word, count ) <- countMap )
context.write( new Text( key ), new LongWritable( value ) )
countMap = collection.mutable.Map[String, Long]()
}
}
上記Mapperを利用して-Xmx200M指定でWordCountを実行した場合、実行時間は90秒(512Mで実行した場合より遅く、Combiner利用時よりは速い)になった。setupは1つのMapperで8〜9回ほど呼ばれていた。
上記MapperとCombinerも併用したケースでは、Mapper単体の時とほぼ同じ時間(89秒)になった。この辺はデータの内容やメモリの乗り切る分量によって効果のあるなしが変わりそうなところ。
とりあえず上記のようなコードであれば、メモリに対する気遣いをある程度は忘れられるかもしれない。