概要
MapReduceした際に出力されるログに関する簡単なまとめ。
サンプルコードはScala2.9.1。
@Date 2011/11/19
@Versions Hadoop0.20, Ubuntu10.04, CDH3
ログの出力方法
Hadoopはcommonsのloggingを利用しています。ということで、普通に下記のような記述でログを出力させることができます。
import org.apache.commons.logging.LogFactory
val log = LogFactory.getLog( this.getClass() )
log.info( "ログを出力するよ" )
書く場所には注意が必要で、例えばMapperのmapメソッドは解析するファイルの行数分だけ呼び出されるので、うっかり中にlog出力を書いて大規模ファイルの解析を実行してしまうと死ぬほどログが吐かれることになります(設定で最大サイズとかは指定できるけど)。
ログの確認(Webブラウザ)
出力されたログはWebブラウザで確認できます。
http://jobtracker:50030/
上記のURL(jobtrackerの部分はJobTrackerを動かしているマシンのホスト名)を開きます。
Logを見たいジョブのJobidをクリックします。すると下図のようなページが開かれます。
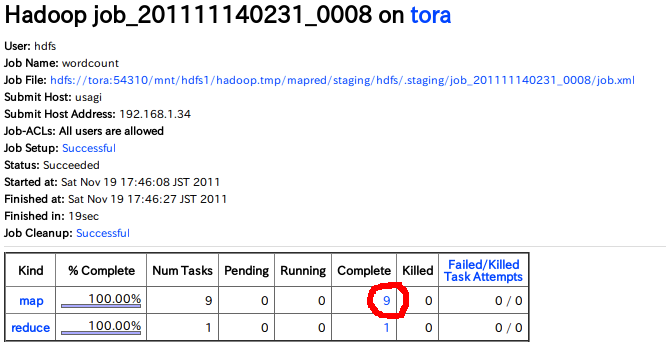
赤丸を書いてある部分の数字をクリックすると、TaskTrackerがこなしたTaskが一覧で表示されます。
適当なTaskを1つ選び、表示されたページのTask Logsの箇所をクリックすると、実際のログが表示されます。
ここにはログだけでなく標準出力や標準エラー出力の情報も出てきます。ということでうっかりmap関数の中に標準出力を書いてしまうと、やはりものすごい量のログが吐かれてしまうことになります。
ログの確認(ファイル)
ログファイル自体は各TaskTrackerのローカルに出力されています。
CDH3の場合は、以下のパスに格納されます。
/usr/lib/hadoop-0.20/logs/userlogs/${job-id}/${task-attempts}
上記ディレクトリの中に、stdout、stderr、syslogの3つがいます。
stdoutは名前の通り標準出力。printlnとかした値はここに入ります。
stderrは標準エラー出力。printStackTraceとかした値はここに入ります。
syslogにはlog4jで出力したログが入ります。デフォルトのログレベルはinfoになっているようです。
ログのファイルの保存期間
上記のログファイルは時間が経つと削除されます(デフォルトだと24時間)。
mapred-site.xmlにmapred.userlog.retain.hoursというパラメータを設定してvalueに時間を記述すると、この時間は変更できるそうです。
あと、mapred.userlog.limit.kbを指定すると、ログファイルのサイズの上限も設定できるようです。
ログファイルの容量が気になる場合は指定することになるかも。