概要
Eclipse + Maven + ScalaでMapReduceしてみた。
割と強引なやり方なのでこれが正しいのかと言われると微妙ですが、とりあえず我が家の環境ではそれなりに動いてくれてます。
JavaやHadoopの導入は済んでいるものとします。済んでない場合は、とりあえず擬似分散モードなどで動く状態を作りましょう。本例ではCDH3を使って完全分散モード上で動かしています。
@Date 2011/11/02
@Versions CDH3, Scala2.9.1, Eclipse3.7, Maven2
@Updated 2012/02/26 Mavenのscopeでprovidedを使うよう変更
必要なものを揃える
まずMaven2をインストールします。sbtでもできると思います。
$ sudo apt-get install maven2
次にEclipseをダウンロードします。これを書いている時点ではScala IDE for Eclipseの対応バージョンが3.6と3.7なので3.7 Classicを落とします。
http://www.eclipse.org/downloads/packages/eclipse-classic-371/indigosr1
落としたら適当な場所に解凍した後、中のeclipse.iniを編集します。
$ cd eclipse
$ vi eclipse.ini
// 変更前
-Xms40m
-Xmx384m
// 変更後
-Xms384m
-Xmx1024m
Scala IDE for Eclipseはけっこうメモリを使います。なので384のままだと軽々しくOutOfMemoryを吐いたりします。そのためXmxの数字を上げておきます。
修正できたらeclipseファイルをダブルクリックしてEclipseを立ち上げます。
m2eのインストール
EclipseのMaven用のプラグインをインストールします。
メニューバーのHelp → Install New Softwareを選択。
Work withでIndigoを選択してしばし待つとパッケージが表示されるので、Collaborationからm2e - Maven Integration for Eclipseとm2e - slf4j over logback loggin (Optional)を選択してNext。
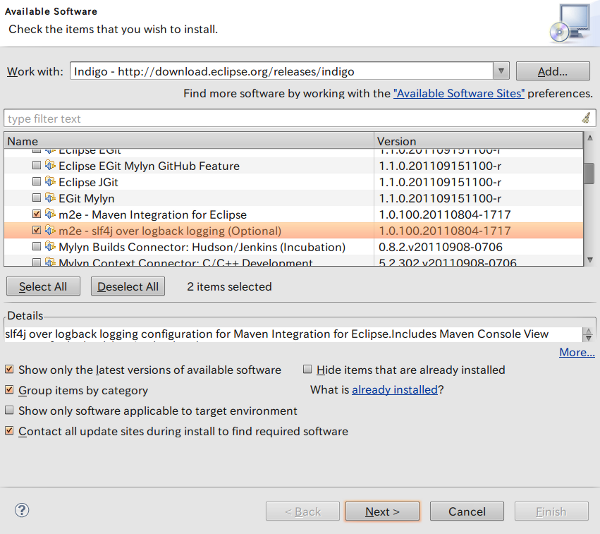
Next → Accept → Finishと進むとインストールが開始します。終わったらRestart Nowを選択。
これでm2eのインストールが完了しました。
Scala IDE for Eclipseのインストール
EclipseでScalaの開発を行うためのプラグインをインストールします。
以下のサイトでUpdate SitesのURLを調べてコピーしてきます。
http://www.scala-ide.org/
自分が調べた時は、「http://download.scala-ide.org/releases-29/stable/site」でした。
EclipseのメニューバーのHelp → Install New Softwareを選択。
右側にいるAddボタンをクリック → Nameに何か適当な言葉(Scalaとか)を入力、Locationに上記サイトから拾ってきたURLをペーストして、OK。
しばし待つと3つほど項目が表示されるので、すべてチェックしてNext。
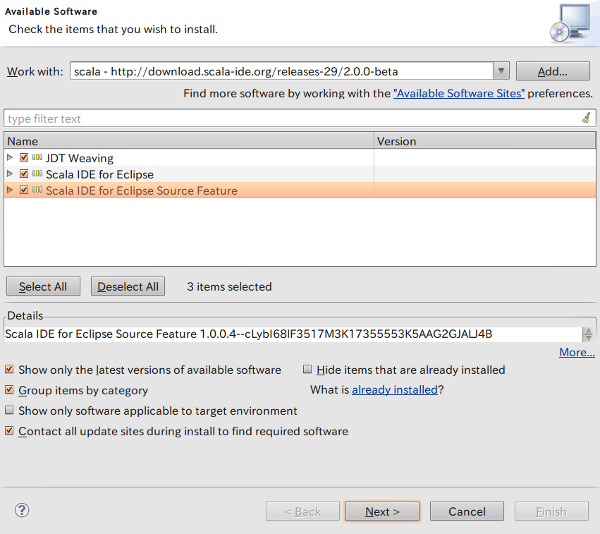
Next → Accept → Finishと進むとインストールが開始します。終わったらRestart Nowを選択。
これでScala IDE for Eclipseのインストールが完了しました。
Mavenプロジェクトの作成
準備が出来たので、さっそくMapReduceっぽい処理を実行させてみます。
まず、Mavenプロジェクトを作成します。メニューバーのFile → New → Other → Maven → Maven Projectを選択してNext。
Create a simple projectにチェックを入れてNext。
下記のようにGroup IdとArtifact Idに任意の名前(例ではGroup Idにjp.mwsoft.sample、Artifact Idにmapred-sampleと付けている)を付けてFinish。
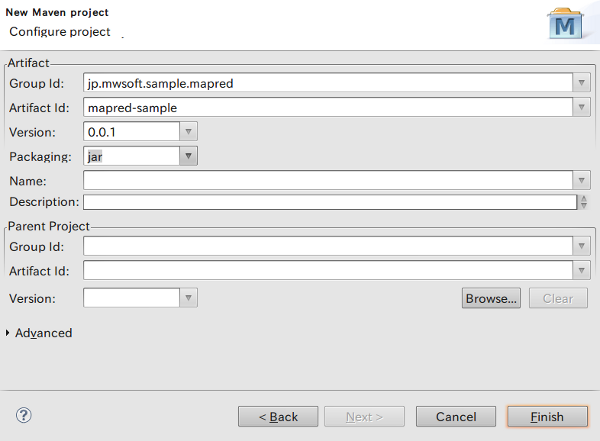
プロジェクトが生成されたら、出来上がったプロジェクトを右クリック → Configure → Add Scala Nature。これでScalaのソースをコンパイルできる状態になります。
次にプロジェクトを開くとソースフォルダがsrc/main/javaやsrc/test/javaとなっているので、フォルダを選択してF2を押してsrc/main/scalaとsrc/test/scalaにrenameします。
最後に、パースペクティブをScalaにします。メニューバーのWindow → Open Perspective → Other → Scalaと選んでOK。
これでScalaを開発できる風のMaven環境が整いました。
pom.xmlの編集
pom.xmlを編集して、Hadoop関連のjarを依存関係に追加します。
まず、出来上がったプロジェクトを開いてpom.xmlをダブルクリック。開いたビューの下部にあるメニューからpom.xmlを選択してXMLを直接編集できる状態にします。
project要素の中に、以下のrepositoryとdependencyを追加します。
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/content/repositories/releases/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>0.20.2-cdh3u3</version>
<scope>provided</scope>
</dependency>
</dependencies>
これでHadoopでの開発に必要なjarが一通り依存関係に追加されました。
Hadoopのdependencyにはprovidedを設定しておきます。providedはコンパイルの際だけ依存性を解決するモードです。
上記の設定は最新でない可能性があります。最新の情報は下記URLに載ってたらいいなぁ。
https://ccp.cloudera.com/display/CDHDOC/Using+the+CDH3+Maven+Repository
ここで指定するHadoopのバージョンと、実際にNameNodeとかJobTrackerとかを動かしているHadoopのバージョンが違うと、後で分散環境で動かそうとした時に怒られます。
CDH3を利用している前提で書いていますが、普通にHadoopを導入した場合は以下のサイトを参考にdependencyを設定します。
http://mvnrepository.com/artifact/org.apache.hadoop/hadoop-core
追加したら一度メニューバーのProject → Cleanを選択します。何か依存関係を編集した後はCleanをしないと反映されない場合があります。
簡単なMapReduceのソースを書いてみる
試しに良くサンプルで用いられるWordCountのコードを書いてみましょう。
src/main/scala上で右クリック → New → Package → 適当なパッケージ名(本例ではjp.mwsoft.sample.mapred)を入力してFinish。
作成したパッケージ上で右クリック → New → Scala Object → NameにWordCountと入力してFinish。
生成されたWordCount.scalaに以下のコードを記述して実行します。これは「data/in」ディレクトリにの中に置かれたファイルを読み込んで単語の数を集計し、5回以上出現するものを「data/out」ディレクトリに出力するというコードです。
今回は環境設定が主題なのでコードの説明は保留します。これを実行するとローカルモードでMapReduce的な処理が実行されdata/outディレクトリに集計した単語数が出力されます。
package jp.mwsoft.sample.mapred
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.{ LongWritable, Text }
import org.apache.hadoop.mapreduce.{ Job, Mapper, Reducer }
import org.apache.hadoop.mapreduce.lib.input.{ FileInputFormat, TextInputFormat }
import org.apache.hadoop.mapreduce.lib.output.{ FileOutputFormat, TextOutputFormat }
object WordCount extends App {
val conf = new Configuration(true)
val job = new Job(conf, "wordcount")
FileInputFormat.setInputPaths(job, new Path("data/in"))
FileOutputFormat.setOutputPath(job, new Path("data/out"))
job.setJarByClass(classOf[WordCountMapper])
job.setOutputKeyClass(classOf[Text])
job.setOutputValueClass(classOf[LongWritable]);
job.setInputFormatClass(classOf[TextInputFormat])
job.setOutputFormatClass(classOf[TextOutputFormat[Text, Text]])
job.setMapperClass(classOf[WordCountMapper])
job.setReducerClass(classOf[WordCountReducer])
job.waitForCompletion(true)
class WordCountMapper extends Mapper[LongWritable, Text, Text, LongWritable] {
private val word = new Text()
private val one = new LongWritable(1)
type Context = Mapper[LongWritable, Text, Text, LongWritable]#Context
override def map(key: LongWritable, value: Text, context: Context) {
val line = value.toString()
for (str <- line.split(Array(' ', '\n', '\t'))) {
word.set(str)
context.write(word, one)
}
}
}
class WordCountReducer extends Reducer[Text, LongWritable, Text, LongWritable] {
type Context = Reducer[Text, LongWritable, Text, LongWritable]#Context
override def reduce(key: Text, values: java.lang.Iterable[LongWritable], context: Context) {
val ite = values.iterator()
var sum = 0L
while (ite.hasNext()) {
sum += ite.next().get()
}
if (sum >= 5) context.write(key, new LongWritable(sum))
}
}
}
試しに下記のファイルをdata/inディレクトリに配置して実行してみました。
data/inに入れたファイル
結果ファイル
実行する際は普通にEclipse上からCtrl+F11で実行できます。
分散環境で動くjarファイルの作成
Scalaで作ったソースはscala-library.jarをクラスパスに通しておかないとhadoop jarコマンドで動かすことはできません。なのでHadoopで動かそうとするとひと手間いります。
面倒なので今回はMavenのassemblyプラグインを利用して、依存関係にあるクラスをすべてまとめてしまう方法で、分散環境で動くjarファイルを作成してみます。
まずはpom.xmlの編集。dependencyにscala-libraryを追加し、pluginにmaven-compiler-pluginとmaven-scala-pluginを入れます。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>jp.mwsoft.sample</groupId>
<artifactId>mapred-sample</artifactId>
<version>0.0.1</version>
<properties>
<scala.version>2.9.1</scala.version>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/content/repositories/releases/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>0.20.2-cdh3u3</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.2.1</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
</project>
これでコマンドライン上からmvn assembly:assemblyすればjarファイルを生成できるようになりました。
上記の記述を行うとEclipseが「pom.xmlにエラーがあるぞ」とクレームを付けてくる場合があります。その時はProbremsのView上で出ているエラーを右クリックしてQuick Fix → 出てきたダイアログでPamanently mark goal...を選ぶ → Finishで消えます。複数警告が出ている場合は何回か繰り返してQuick Fixする必要があります。
pom.xmlの編集が終わったら、端末を開いてプロジェクトがあるフォルダにcdし、下記のコマンドを実行します。
$ mvn assembly:assembly
するとtargetディレクトリの下に、mapred-sample-0.0.1-jar-with-dependencies.jarのような長い名前のファイルが出来上がります。この子は依存性も含めて全部のクラスが放り込まれたjarファイルです。
dependencyのscopeにprovidedを指定したライブラリは上記jarに含まれません。
さっそく実行してみましょう。
// とりあえずプログラムに渡す入力ファイルをHDFS上に置く
// 何か英語の文章が書かれたsample.txtというファイルを用意しておくこと
$ sudo -u hdfs hadoop fs -mkdir data/in
$ sudo -u hdfs hadoop fs -put sample.txt data/in/
// jarファイルを実行してみる
$ sudo -u hdfs hadoop jar target/mapred-sample-0.0.1-jar-with-dependencies.jar jp.mwsoft.sample.mapred.WordCount
NameNodeでhttp://localhost:50030/を見ると、ちゃんと実行した処理が表示されていることが分かります。
結果もちゃんとHDFS上に出力されます。
// 結果ファイルの確認
$ sudo -u hdfs hadoop fs -ls data/out
Found 3 items
-rw-r--r-- 1 hdfs supergroup 0 2011-11-15 01:06 /user/hdfs/data/out/_SUCCESS
drwxr-xr-x - hdfs supergroup 0 2011-11-15 01:06 /user/hdfs/data/out/_logs
-rw-r--r-- 1 hdfs supergroup 169 2011-11-15 01:06 /user/hdfs/data/out/part-r-00000
// catしてみる
$ sudo -u hdfs hadoop fs -cat data/out/part-r-00000
一応、AmazonのElasticMapReduceでもこの方法で動きました。dependencyのところはorg.apache.hadoopのhadoop-coreに変更しましたが。
開発してるマシンにもhadoopを導入しておくと、その場でhadoop jarコマンドで実行できるので便利です。
我が家では開発機にDataNodeとTaskTrackerを入れてます。それらを立ち上げていなくても、設定ファイルだけしっかりNameNodeやJobTrackerを指すようにしておけば、hadoopコマンドは実行可能です。
下記のような適当なシェルを書けばjarの生成から実行まで自動化できたりもします。
#!/usr/bin/env bash
version=0.0.1
username=user_name
if [ $# -ne 1 ]; then
echo "usage: sudo ./mapred-run.sh com.sample.ClassName"
exit 1
fi
projectname=`basename \`pwd\``
sudo -u $username mvn assembly:assembly
sudo -u hdfs hadoop jar target/$projectname-$version-jar-with-dependencies.jar $1