IgoのLucene用Analyzerを使ってみた
概要
先日紹介したIgoについて、Lucene用のAnalyzerが用意されているようなので導入してみる。
@Date 2010/12/20
@Env Lucene3.0.3 / Igo0.4.2 / Fedora14
@Date 2010/12/20
@Env Lucene3.0.3 / Igo0.4.2 / Fedora14
インストール
まず、下記のサイトからLuceneを落とす。自分が落としたのは、lucene-3.0.3.tar.gz。
http://www.apache.org/dyn/closer.cgi/lucene/java/
// 解凍
$ lucene-3.0.3.tar.gz
次にIgo本体を落とす。自分が落としたのは、igo-0.4.2.jar。
http://sourceforge.jp/projects/igo/releases/
最後に、下記ダウンロードサイトから、igo-analyzer-0.0.1-src.tar.gzを落とす。
http://sourceforge.jp/projects/igo/releases/
srcの方を落としてるのは、自分の環境だと落としたjarを使うとCharSequenceでNoSuchMethodErrorが起きた(1.4でコンパイルしたのを1.5以降で呼び出すと一部の環境で起こるエラーだっけ? ちゃんとは調べてない)ので自前でAntすることに。
//解凍とAntの準備
$ igo-analyzer-0.0.1-src.tar.gz
$ cd igo-analyzer-0.0.1-src
$ mkdir lib
上のような感じで落としたソースを解凍してlibディレクトリを作る。で、libディレクトリの中に以下のjarファイルを放り込む。(バージョンの違いは適宜読み替えてください)
// libディレクトリに入れるjar
・igo-0.4.2.jar
・lucene-core-3.0.3.jar
最終的にパス構成はこんな感じになる。
で、libディレクトリを-libに指定しつつAnt
$ ant -lib lib
これで欲しかった、igo-analyzer-0.0.1.jarが作成される。
http://www.apache.org/dyn/closer.cgi/lucene/java/
// 解凍
$ lucene-3.0.3.tar.gz
次にIgo本体を落とす。自分が落としたのは、igo-0.4.2.jar。
http://sourceforge.jp/projects/igo/releases/
最後に、下記ダウンロードサイトから、igo-analyzer-0.0.1-src.tar.gzを落とす。
http://sourceforge.jp/projects/igo/releases/
srcの方を落としてるのは、自分の環境だと落としたjarを使うとCharSequenceでNoSuchMethodErrorが起きた(1.4でコンパイルしたのを1.5以降で呼び出すと一部の環境で起こるエラーだっけ? ちゃんとは調べてない)ので自前でAntすることに。
//解凍とAntの準備
$ igo-analyzer-0.0.1-src.tar.gz
$ cd igo-analyzer-0.0.1-src
$ mkdir lib
上のような感じで落としたソースを解凍してlibディレクトリを作る。で、libディレクトリの中に以下のjarファイルを放り込む。(バージョンの違いは適宜読み替えてください)
// libディレクトリに入れるjar
・igo-0.4.2.jar
・lucene-core-3.0.3.jar
最終的にパス構成はこんな感じになる。
|-- COPYING
|-- build.xml
|-- lib
| |-- igo-0.4.2.jar
| `-- lucene-core-3.0.3.jar
`-- src
`-- net
`-- reduls
`-- igo
`-- analysis
`-- ipadic
|-- IpadicAnalyzer.java
`-- IpadicTokenizer.java
で、libディレクトリを-libに指定しつつAnt
$ ant -lib lib
これで欲しかった、igo-analyzer-0.0.1.jarが作成される。
環境設定
開発環境はEclipseを利用。
まず適当なプロジェクトを作成し、libディレクトリを掘ってさっきの3つのjarを入れる。で、3つのjarをクラスパスに追加する。
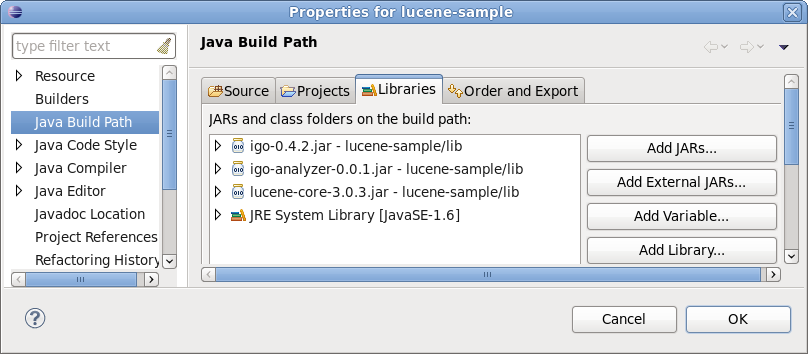
上図のような感じで。これでIgoのAnalyzerが使えるようになった。
まず適当なプロジェクトを作成し、libディレクトリを掘ってさっきの3つのjarを入れる。で、3つのjarをクラスパスに追加する。
上図のような感じで。これでIgoのAnalyzerが使えるようになった。
インデックス作成クラスの実装
Javaで呼び出す時は下のソースみたいな感じになる。内容はIgoのAnalyzer(IpadicAnalyzerという名前)を使って、2つほど短いドキュメントを追加しているだけの簡易な処理。
尚、Taggerの引数の「ipadic」は辞書ファイルのパスをしている。辞書ファイルやTaggerについてはIgoの導入の方を参照されたし。
$ lukeall-1.0.1.jar org.getopt.luke.Luke -index index
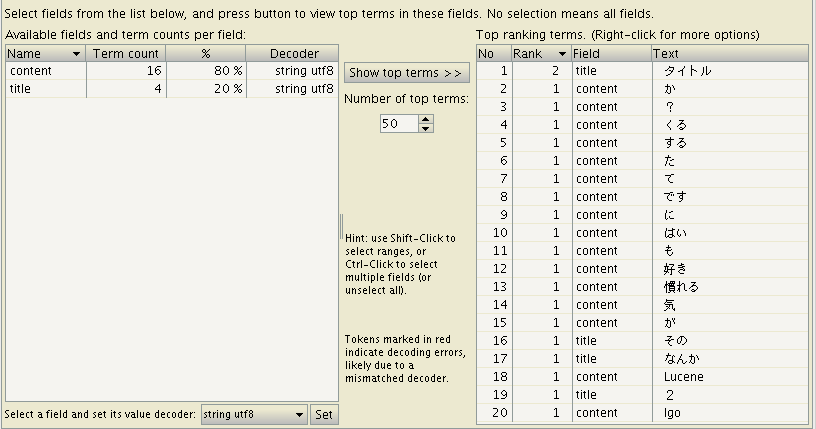
「タイトル」とか「慣れる」とか「好き」のように、ちゃんと形態素解析されたっぽいインデックスになってる。ということで、処理はうまくいってるっぽい。
ちなみにLukeはLuceneのインデックスをGUIで表示してくれる子。下記URLから落とせる。
http://code.google.com/p/luke/downloads/list
尚、Taggerの引数の「ipadic」は辞書ファイルのパスをしている。辞書ファイルやTaggerについてはIgoの導入の方を参照されたし。
import java.io.File;
import net.reduls.igo.Tagger;
import net.reduls.igo.analysis.ipadic.IpadicAnalyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
/**
* Igoを利用したインデックス作成
* @author mwSoft
*/
public class CreateIndexTest {
/**
* インデックスを作成する
*/
public static void createIndex() throws Exception {
// Analyzerを用意
Analyzer analyzer = new IpadicAnalyzer(new Tagger("ipadic"));
// インデックスディレクトリの設定
Directory dir = new SimpleFSDirectory(new File("index"));
IndexWriter writer = new IndexWriter(dir, analyzer, MaxFieldLength.LIMITED);
// titleとcontentというフィールドを持つドキュメントをインデックスに追加してみる
Document doc = new Document();
doc.add(new Field("title", "なんかタイトル",
Field.Store.YES, Field.Index.ANALYZED));
doc.add(new Field("content", "Igoにも慣れてきた気がする",
Field.Store.YES, Field.Index.ANALYZED));
writer.addDocument(doc);
// 1つだと寂しいので、もう1つ追加してみる
Document doc2 = new Document();
doc2.add(new Field("title", "タイトルその2",
Field.Store.YES, Field.Index.ANALYZED));
doc2.add(new Field("content", "Lucene好きですか? はい好きです",
Field.Store.YES, Field.Index.ANALYZED));
writer.addDocument(doc2);
// しゅーりょー
writer.close();
}
/** main */
public static void main(String[] args) throws Exception {
createIndex();
}
}
$ lukeall-1.0.1.jar org.getopt.luke.Luke -index index
「タイトル」とか「慣れる」とか「好き」のように、ちゃんと形態素解析されたっぽいインデックスになってる。ということで、処理はうまくいってるっぽい。
ちなみにLukeはLuceneのインデックスをGUIで表示してくれる子。下記URLから落とせる。
http://code.google.com/p/luke/downloads/list
検索クラスの実装
インデックスを作っただけでは片手落ちなので、検索もしてみる。
ヒット数 : 1
タイトルその2
Lucene好きですか? はい好きです
「Luce」や「タイト」のようなインデックスされてる文字の一部で検索するとちゃんと0件が返る。どうやらちゃんと動いてるっぽい。
import java.io.File;
import net.reduls.igo.Tagger;
import net.reduls.igo.analysis.ipadic.IpadicAnalyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Searcher;
import org.apache.lucene.search.TopScoreDocCollector;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* Igoを利用した検索処理
* @author mwSoft
*/
public class SearchTest {
/**
* 検索の実行
* @param keyword キーワード
* @throws Exception
*/
public static void search( String keyword ) throws Exception {
// 検索の準備
IndexReader reader = IndexReader.open(FSDirectory
.open(new File("index")), true);
Searcher searcher = new IndexSearcher(reader);
// 検索クエリの準備
Analyzer analyzer = new IpadicAnalyzer(new Tagger("ipadic"));
QueryParser parser = new QueryParser(Version.LUCENE_30, "content", analyzer);
Query query = parser.parse(keyword);
// 検索の実行
TopScoreDocCollector collector = TopScoreDocCollector.create(1000, false);
searcher.search(query, collector);
// 検索ヒット数の出力
System.out.println( "ヒット数 : " + collector.getTotalHits() );
// 検索結果(上位10件)の出力
ScoreDoc[] hits = collector.topDocs(0, 10).scoreDocs;
for( ScoreDoc hit : hits ) {
Document doc = searcher.doc(hit.doc);
System.out.println( doc.get("title") );
System.out.println( doc.get("content") );
}
}
/** main */
public static void main(String[] args) throws Exception {
// 検索ワードを指定して検索実行
search("Lucene");
}
}
ヒット数 : 1
タイトルその2
Lucene好きですか? はい好きです
「Luce」や「タイト」のようなインデックスされてる文字の一部で検索するとちゃんと0件が返る。どうやらちゃんと動いてるっぽい。
まとめ
というわけで、IgoでLuceneのインデックスを扱ってみた。Igoを導入してAnalyzerをAntさえしてしまえば、あとはCJKAnalyzerなんかを使うのと同じ感覚で利用できる。割とお手軽。
実はGoSenのAnalyzerは使ったことがないので、IgoとGoSen、どっちが良いのかはわからない。とりあえずSenは導入が面倒だったからパス。機会があればGoSenも使ってみたい。
実はGoSenのAnalyzerは使ったことがないので、IgoとGoSen、どっちが良いのかはわからない。とりあえずSenは導入が面倒だったからパス。機会があればGoSenも使ってみたい。

