概要
MeCab0.994で再学習機能が入ったので、その辺りも含めてMeCabの辞書カスタマイズ方法を洗ってみる。
今回取り扱うのは、CSV形式で新しい単語の情報を記述して辞書を生成(mecab-dict-index)する方法と、文章の解析結果を用意してそれを利用して学習(mecab-cost-train)する方法。
Linuxで実行。Windowsは知らない。
@CretedDate 2012/06/24
@Env MeCab0.994, Ubuntu10.04
単語追加用のCSVファイルを作成する
まずはCSVファイルを手書きして、MeCabの辞書に新しい単語を追加してみる。
やり方は公式サイトに載っている。
今回は例として「アメリカの大統領の名前くらい登録しておきたいよね」ということでバラクとオバマという2つの固有名詞を追加してみる。両単語はIPA辞書では未知語になっている。
$ echo "バラク・オバマ" | mecab -U"%M\t%H\t未知語\n"
バラク 名詞,一般,*,*,*,*,* 未知語
・ 記号,一般,*,*,*,*,・,・,・
オバマ 名詞,固有名詞,組織,*,*,*,* 未知語
EOS
(コマンドの説明 : mecab -Uで未知語の場合の表示形式を指定できる。上記の場合は表層文字と品詞を書いて、その後ろに「未知語」と表示しなさいという指定)
追加する際は、既存の辞書の情報を参照すると楽。ダウンロードページからmecab-ipadic-2.7.0-20070801.tar.gzを落としてきて、その中に入っているCSVを参照する。
名前に関する情報はNoun.name.csvに入っている。同じ大統領ということで、ジョージとブッシュがどう登録されているかを見てみる。
ジョージ,1291,1291,3632,名詞,固有名詞,人名,名,*,*,ジョージ,ジョージ,ジョージ
ブッシュ,1290,1290,4654,名詞,固有名詞,人名,姓,*,*,ブッシュ,ブッシュ,ブッシュ
意味は左から、表層文字,左文脈ID,右文脈ID,コスト,品詞(以下、略)。
これを参考にして下記のようなファイルを作る。バラクはジョージほど頻出ではないので、他の似た名前を参考にしつつ少し大きめの5000というコストを振った。
バラク,1291,1291,5000,名詞,固有名詞,人名,名,*,*,バラク,バラク,バラク
オバマ,1290,1290,5000,名詞,固有名詞,人名,姓,*,*,オバマ,オバマ,オバマ
余談だけどMeCabの辞書の多くは、海外の人名を扱い慣れていない。日本と海外の人名を同列に扱っているため「姓 - 名」の並びが連接しやすくなっているため。
人名を多く登録するとカタカナの未知語を妙な区切り方をして名前だと推定してしまうことがけっこうある。日本人名と海外人名を別の品詞分類として登録したいところだけど、割と手間がかかるので今回はやらない。
話戻して、上のバラクとオバマのCSV文字列をファイルに書き出す。ファイル名は仮にname.csvとする。
ユーザ辞書に追加する
MeCabにはシステム辞書とユーザ辞書が存在する。システム辞書は大素になる辞書。ユーザ辞書は状況に応じて個別に指定できる辞書。
形態素解析をする時、システム辞書は必ず利用され、1度に1つのシステム辞書しか指定できない。ユーザ辞書は任意で使用し、1度に複数(カンマ区切り)利用することもできる。
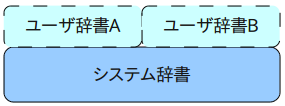
ユーザ辞書を作成する際は、mecab-dict-indexを利用する。
$ /usr/local/libexec/mecab/mecab-dict-index \
-d システム辞書のパス \
-u 出力するユーザ辞書 \
-f CSVの文字コード \
-t 辞書の文字コード \
作成したCSVファイル
LinuxにソースからMeCabを入れた場合(辞書はUTF-8で入れたものとする)は、こんな風に実行する。
$ /usr/local/libexec/mecab/mecab-dict-index \
-d /usr/local/lib/mecab/dic/ipadic \
-u name.dic \
-f utf-8 \
-t utf-8 \
name.csv
上記コマンドを実行すると、前の項で作ったname.csvというファイルが読み込まれて、-uで指定したname.dicというユーザ辞書ファイルが生成されます。
ユーザ辞書はmecabコマンドを打つ際に、-uで指定する。
# ユーザ辞書未指定時
$ echo "バラク・オバマ大統領" | mecab
バラク・オバマ 名詞,一般,*,*,*,*,*
大統領 名詞,一般,*,*,*,*,大統領,ダイトウリョウ,ダイトーリョー
EOS
# ユーザ辞書指定時
$ echo "バラク・オバマ大統領" | mecab -u name.dic
バラク 名詞,固有名詞,人名,名,*,*,バラク,バラク,バラク
・ 記号,一般,*,*,*,*,・,・,・
オバマ 名詞,固有名詞,人名,姓,*,*,オバマ,オバマ,オバマ
大統領 名詞,一般,*,*,*,*,大統領,ダイトウリョウ,ダイトーリョー
EOS
こんな感じで、ユーザ辞書を反映した結果が得られる。
システム辞書とユーザ辞書の双方に単語があった場合はユーザ辞書が優先されるっぽい。たとえばユーザ辞書に「ジョージ」をコスト3000で登録した場合(IPA辞書ではコスト3632)、結果は下記のようになる。
$ echo "ジョージ・ブッシュ" | mecab -u name.dic -F "%M\t%c\n"
ジョージ 3000
・ -807
ブッシュ 4654
EOS
-Fを使って単語の生起コストを出力するように指定している。ジョージのコストはユーザ辞書に登録した内容で上書きされ、3000になっている。
システム辞書に追加する
システム辞書に追加する場合はmecab-dict-indexでもいけるけど、辞書を再度makeした方が楽な気がする。
自動的にフォルダ内の拡張子がCSVのファイルが辞書に追加されるので、落としてきたmecab-ipadic-2.7.0-20070801の配下に追加のCSVファイルを置いてmakeすれば、自動的にその単語がシステム辞書に追加される。
試しにユーザ辞書の項で使ったバラク・オバマのCSVを置いてみます。この時、追加するCSVの文字コードは他のCSVファイルと揃える(Linux用のIPA辞書ならEUC-JP)必要があります。
# 前に作ったname.csvをIPA辞書の配下に置く
$ cp name.csv mecab-ipadic-2.7.0-20070801/
$ cd mecab-ipadic-2.7.0-20070801
# 初make時は、configureとmakeをする
$ ./configure --with-charset=utf8
$ make
$ sudo make install
# 2度目以降はmake cleanとmakeをする
$ make clean
$ make
$ sudo make install
上記のように、CSVを配置 → make clean → make → sudo make install という手順を実行することで、システム辞書に新しく単語を追加することができます。
公式サイトではmecab-dict-indexを利用してシステム辞書を再作成する方法も載ってます。
動詞の追加
名詞の追加は1つ単語を入れるだけなので楽ですが、動詞は活用形も含めて入れないといけないので、けっこう大変です。
例として、「使う」という動詞を見てみます。動詞はIPA辞書だとVerb.csvというファイルに記述されています。
Verb.csvの中から、基本形(CSVの11個目の値)が「使う」になっている行をgrepしてみます。
$ grep ,使う, Verb.csv
使う,802,802,6696,動詞,自立,*,*,五段・ワ行ウ音便,基本形,使う,ツカウ,ツカウ
使わ,806,806,6707,動詞,自立,*,*,五段・ワ行ウ音便,未然形,使う,ツカワ,ツカワ
使お,804,804,6710,動詞,自立,*,*,五段・ワ行ウ音便,未然ウ接続,使う,ツカオ,ツカオ
使い,812,812,5983,動詞,自立,*,*,五段・ワ行ウ音便,連用形,使う,ツカイ,ツカイ
使う,810,810,6696,動詞,自立,*,*,五段・ワ行ウ音便,連用タ接続,使う,ツカウ,ツカウ
使え,800,800,7360,動詞,自立,*,*,五段・ワ行ウ音便,仮定形,使う,ツカエ,ツカエ
使え,808,808,7360,動詞,自立,*,*,五段・ワ行ウ音便,命令e,使う,ツカエ,ツカエ
使う,817,817,6696,動詞,自立,*,*,五段・ワ行促音便,基本形,使う,ツカウ,ツカウ
使わ,823,823,6707,動詞,自立,*,*,五段・ワ行促音便,未然形,使う,ツカワ,ツカワ
使お,820,820,6710,動詞,自立,*,*,五段・ワ行促音便,未然ウ接続,使う,ツカオ,ツカオ
使い,832,832,5983,動詞,自立,*,*,五段・ワ行促音便,連用形,使う,ツカイ,ツカイ
使っ,829,829,6677,動詞,自立,*,*,五段・ワ行促音便,連用タ接続,使う,ツカッ,ツカッ
使え,814,814,7360,動詞,自立,*,*,五段・ワ行促音便,仮定形,使う,ツカエ,ツカエ
使え,826,826,7360,動詞,自立,*,*,五段・ワ行促音便,命令e,使う,ツカエ,ツカエ
なんか14行も出てきました。活用形、いっぱいです。
動詞はそれぞれに活用形が違っているので、すべてが「使う」と同じ活用をするわけではありません。例えば「倒す」の場合は下記のようになります。
$ grep ,倒す, Verb.csv
倒す,731,731,7195,動詞,自立,*,*,五段・サ行,基本形,倒す,タオス,タオス
倒さ,733,733,7194,動詞,自立,*,*,五段・サ行,未然形,倒す,タオサ,タオサ
倒そ,732,732,7194,動詞,自立,*,*,五段・サ行,未然ウ接続,倒す,タオソ,タオソ
倒し,735,735,7253,動詞,自立,*,*,五段・サ行,連用形,倒す,タオシ,タオシ
倒せ,729,729,7194,動詞,自立,*,*,五段・サ行,仮定形,倒す,タオセ,タオセ
倒せ,734,734,7194,動詞,自立,*,*,五段・サ行,命令e,倒す,タオセ,タオセ
倒しゃ,730,730,7195,動詞,自立,*,*,五段・サ行,仮定縮約1,倒す,タオシャ,タオシャ
動詞を追加する際は、似ている活用をする動詞を思い浮かべてそれを真似すると楽です。
例えば「disる」(既に死語だろうか?)という動詞を加える場合は、「disらない」「disられる」「disろう」などに活用される五段・ラ行になると思われます。
「滑る」あたりが活用形的に似ているような気がしたので、それを真似て下記のような記述を作ってみました。
disる,772,772,7072,動詞,自立,*,*,五段・ラ行,基本形,disる,ディスル,ディスル
disら,780,780,7072,動詞,自立,*,*,五段・ラ行,未然形,disる,ディスラ,ディスラ
disん,782,782,7072,動詞,自立,*,*,五段・ラ行,未然特殊,disる,ディスン,ディスン
disろ,778,778,7072,動詞,自立,*,*,五段・ラ行,未然ウ接続,disる,ディスロ,ディスロ
disり,788,788,6869,動詞,自立,*,*,五段・ラ行,連用形,disる,ディスリ,ディスリ
disっ,786,786,7072,動詞,自立,*,*,五段・ラ行,連用タ接続,disる,ディスッ,ディスッ
disれ,768,768,7079,動詞,自立,*,*,五段・ラ行,仮定形,disる,ディスレ,ディスレ
disれ,784,784,7079,動詞,自立,*,*,五段・ラ行,命令e,disる,ディスレ,ディスレ
disりゃ,770,770,7072,動詞,自立,*,*,五段・ラ行,仮定縮約1,disる,ディスリャ,ディスリャ
disん,774,774,7072,動詞,自立,*,*,五段・ラ行,体言接続特殊,disる,ディスン,ディスン
dis,776,776,7356,動詞,自立,*,*,五段・ラ行,体言接続特殊2,disる,ディス,ディス
これを辞書に加えると、下記のように割と自然と「disる」という言葉が解析されてくれます。
$ echo "disられた" | mecab
disら 動詞,自立,*,*,五段・ラ行,未然形,disる,ディスラ,ディスラ
れ 動詞,接尾,*,*,一段,連用形,れる,レ,レ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
EOS
コストの自動推定
MeCabには既存のModelからコスト値を自動推定する機能がついています。
辞書の推定にはModelファイルが必要になります。ダウンロードページのmecab-ipadic-2.7.0-20070801.model.bz2というファイルがそれです。
あとIPA辞書本体も必要になるので、落としてきて解凍します。
作業しやすいように、下記のようなパス構成にしておきます。workというディレクトリに、解凍したIPA辞書とモデルを置いた感じ。
work
|-- mecab-ipadic-2.7.0-20070801
| |-- AUTHORS
| |-- Adj.csv
| |-- Adnominal.csv
| |-- Adverb.csv
| |-- Auxil.csv
(中略)
| |-- rewrite.def
| |-- right-id.def
| `-- unk.def
`-- mecab-ipadic-2.7.0-20070801.model
我が家では辞書の文字コードはUTF-8にしています。でも、work配下に置いたモデルやCSVファイルはEUC-JP。この違いがたまにミスに繋がるので、全部UTF-8にしてしまいます。
$ cd work
$ nkf --overwrite -Ew mecab-ipadic-2.7.0-20070801/*
$ nkf --overwrite -Ew mecab-ipadic-2.7.0-20070801.model
$ vi mecab-ipadic-2.7.0-20070801.model
# 6行目のeuc-jpをutf-8に変更
準備ができたので本題のコスト推定を始めます。またオバマ大統領に登場してもらって、下記のようなCSVファイル(名前は仮にname.csv、文字コードはutf-8とする)を作成して、workの下に置きます。
バラク,,,,名詞,固有名詞,人名,名,*,*,バラク,バラク,バラク
オバマ,,,,名詞,固有名詞,人名,姓,*,*,オバマ,オバマ,オバマ
見ての通り、左右のIDとコストが省略されています。このファイルとモデルを使って、ユーザ辞書を生成します。
# mecab-ipadic-2.7.0-20070801からシステム辞書を生成
$ cd work/mecab-ipadic-2.7.0-20070801
$ /usr/local/libexec/mecab/mecab-dict-index -t utf-8 -f utf-8
$ cd ../
# Modelとシステム辞書を使って、ユーザ辞書を生成
$ /usr/local/libexec/mecab/mecab-dict-index -m mecab-ipadic-2.7.0-20070801.model -d mecab-ipadic-2.7.0-20070801 -u name.dic -f utf-8 -t utf-8 name.csv
これでname.dicというユーザ辞書が生成されました。どんなコストが割り振られたか見てみましょう。
$ echo "バラク・オバマ" | mecab -u name.dic -F "%M\t%c\n"
バラク 4181
・ -807
オバマ 4013
EOS
バラクが4181。オバマが4013。なんかそれっぽい数値ですね。
システム辞書の場合はコスト推定はしてくれないようで、「cost field should not be empty」とかエラーが出ました。
再学習機能の利用
MeCab0.994以前は辞書の学習機能を使う場合、全コーパスを放り込まないといけなかったので、ちゃんとしたコーパスを手元に持っている人しか利用することができませんでした。
0.994からは既存のモデル+少量のコーパスを利用して再学習する機能が付きました。元になったコーパスがなくても学習できるので、利用する際の敷居がぐっと低くなりました。

再学習の説明は公式サイトには以下のように書かれています。
再学習は, 現在のパラメータをできるだけ変更せずに新しい学習データにできるだけ適応するような学習が行われます.
試しに下記の文章を使って、再学習をしてみます。ここまで来たら最後までオバマで通そう。
バラク・フセイン・オバマ・ジュニアは、アメリカ合衆国の政治家。第44代大統領。
Wikipedia:バラク・オバマの項より引用
コストの自動推定の項で作成したworkディレクトリで、下記のようにmecabコマンドを発して、形態素解析した結果をファイルに出力します。
今回は仮にobama.copusというファイルに出力することにします。
echo "バラク・フセイン・オバマ・ジュニアは、アメリカ合衆国の政治家。第44代大統領。" | mecab -o obama.copus
解析結果を見ると、バラク・フセイン・オバマ・ジュニアの部分が綺麗に解析されてないので、下記のような望んだ解析結果に修正します。
バラク 名詞,固有名詞,人名,名,*,*,バラク,バラク,バラク
・ 記号,一般,*,*,*,*,・,・,・
フセイン 名詞,固有名詞,人名,姓,*,*,フセイン,フセイン,フセイン
・ 記号,一般,*,*,*,*,・,・,・
オバマ 名詞,固有名詞,人名,姓,*,*,オバマ,オバマ,オバマ
・ 記号,一般,*,*,*,*,・,・,・
ジュニア 名詞,一般,*,*,*,*,ジュニア,ジュニア,ジュニア
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
、 記号,読点,*,*,*,*,、,、,、
アメリカ合衆国 名詞,固有名詞,地域,国,*,*,アメリカ合衆国,アメリカガッシュウコク,アメリカガッシューコク
の 助詞,連体化,*,*,*,*,の,ノ,ノ
政治 名詞,一般,*,*,*,*,政治,セイジ,セイジ
家 名詞,接尾,一般,*,*,*,家,カ,カ
。 記号,句点,*,*,*,*,。,。,。
第 接頭詞,数接続,*,*,*,*,第,ダイ,ダイ
44 名詞,数,*,*,*,*,*
代 名詞,接尾,助数詞,*,*,*,代,ダイ,ダイ
大統領 名詞,一般,*,*,*,*,大統領,ダイトウリョウ,ダイトーリョー
。 記号,句点,*,*,*,*,。,。,。
EOS
この小さなコーパスを使って再学習します。
コーパスだけだと新しい単語は追加されないので、今回追加した新語用のCSVを作っておきます。コストはあとで調節されるので適当に10000にしておきます。
バラク,1291,1291,10000,名詞,固有名詞,人名,名,*,*,バラク,バラク,バラク
オバマ,1290,1290,10000,名詞,固有名詞,人名,姓,*,*,オバマ,オバマ,オバマ
上記内容をwork/mecab-ipadic-2.7.0-20070801にCustom.csvとでも名前を付けて置いておきます。
CSVを追加した状態で、辞書を一度再生成しておきます。
$ cd mecab-ipadic-2.7.0-20070801
$ /usr/local/libexec/mecab/mecab-dict-index -f utf-8 -t utf-8
$ cd ../
この状態で下記のコマンドを実行すると、コーパスを反映したnew_modelという名前のModelファイルが出来上がります。
$ /usr/local/libexec/mecab/mecab-cost-train -M mecab-ipadic-2.7.0-20070801.model -d mecab-ipadic-2.7.0-20070801 -c 1.0 obama.copus new_model
出来上がったnew_modelから辞書を生成します。辞書は仮にcustomという名前のフォルダに辞書を出力することにします。
$ mkdir custom
$ /usr/local/libexec/mecab/mecab-dict-gen -o custom -d mecab-ipadic-2.7.0-20070801 -m new_model
生成された辞書を見てみると、独自に指定したCustom.csvの中身はこんな風になっていました。
バラク,1142,1142,4159,名詞,固有名詞,人名,名,*,*,バラク,バラク,バラク
オバマ,1143,1143,3967,名詞,固有名詞,人名,姓,*,*,オバマ,オバマ,オバマ
なんかそれっぽいスコアが振られてますね。
最後に生成されたcustomディレクトリの中身をmecabから利用できるように、辞書を生成します。
$ cd custom
$ /usr/local/libexec/mecab/mecab-dict-index -f utf-8 -t utf-8
出来上がった辞書を使って、形態素解析をしてみます。-dでcustomディレクトリのパスを指定すれば利用できる。
$ echo "バラク・オバマは、アメリカ合衆国第44代大統領。" | mecab -d custom
バラク 名詞,固有名詞,人名,名,*,*,バラク,バラク,バラク
・ 記号,一般,*,*,*,*,・,・,・
オバマ 名詞,固有名詞,人名,姓,*,*,オバマ,オバマ,オバマ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
、 記号,読点,*,*,*,*,、,、,、
アメリカ合衆国 名詞,固有名詞,地域,国,*,*,アメリカ合衆国,アメリカガッシュウコク,アメリカガッシューコク
第 接頭詞,数接続,*,*,*,*,第,ダイ,ダイ
44 名詞,数,*,*,*,*,*
代 名詞,接尾,助数詞,*,*,*,代,ダイ,ダイ
大統領 名詞,一般,*,*,*,*,大統領,ダイトウリョウ,ダイトーリョー
。 記号,句点,*,*,*,*,。,。,。
EOS
この辞書をデフォルトにしたい場合は、/usr/local/etc/mecabrcを編集して、dicdirにcustomのパスを指定します。