pandasでいろいろplot
概要
pandasとmatplotlibの機能演習のログ。
可視化にはあまり凝りたくはないから、pandasの機能お任せでさらっとできると楽で良いよね。人に説明する為にラベルとか色とか見やすく出す作業とか面倒。
@Versions python 2.7.6, pandas0.14, matplotlib1.4.2
DataFrameをplot
DataFrameに対してplot()と書くだけで概ね描画できる。
とりあえずimport。
%pylab import pandas as pd import numpy as np from matplotlib import pylab as plt
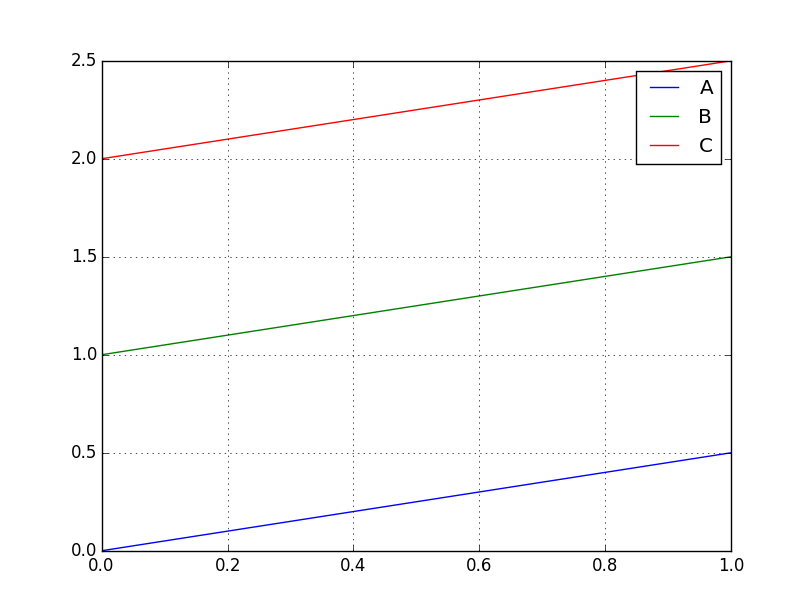
3つのカラムを持つDataFrameをplotしてみる。
df = pd.DataFrame( [ [0, 1, 2], [0.5, 1.5, 2.5] ], columns=('A', 'B', 'C') )
df.plot()
dfの中身はこんな値になる。
A B C
0 0.0 1.0 2.0
1 0.5 1.5 2.5
表示は下図のように、3つのカラムをそれぞれplotしたものになる。
じゃ、中に文字列とか入ってるとどうなるか。
df = pd.DataFrame( [ [0, 1, 'hoge'], [0.5, 1.5, 'fuga'] ], columns=('A', 'B', 'C') )
df.plot()
さっきは3つのカラムすべて数値だったけど、今回はカラムCが文字列になっている。これをplotすると下図のようになる。
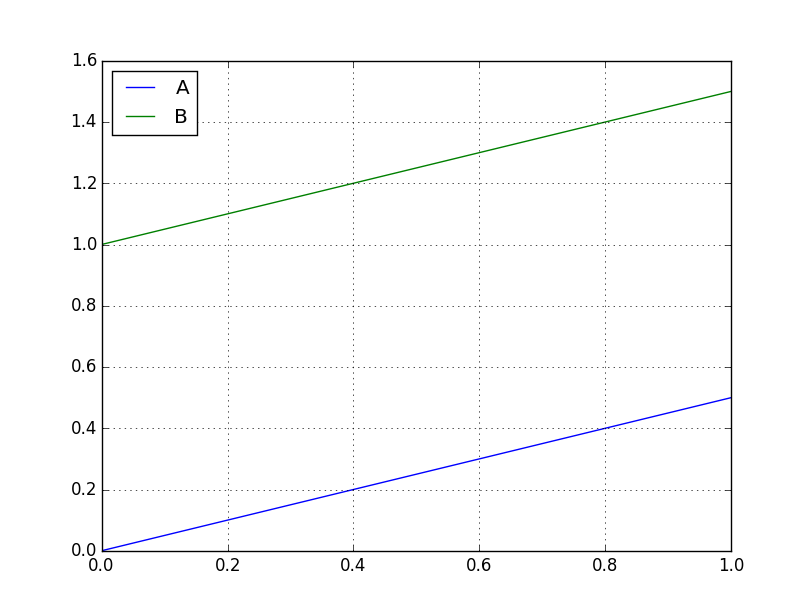
文字列は無視して数値のみplotの対象にしてくれている。
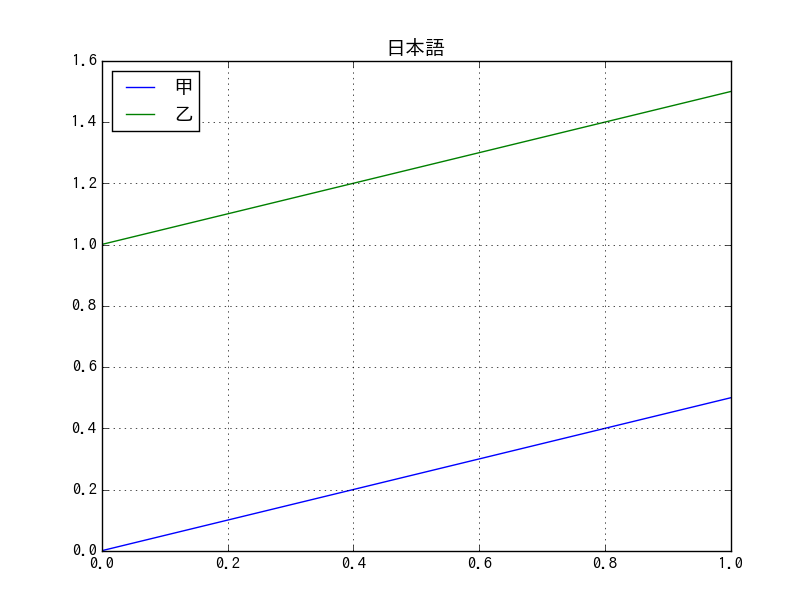
日本語の表示
デフォルトのフォントだと日本語が化けるので、matplotlib.rcで日本語が通じるフォントを設定しておく。
import matplotlib
import pandas as pd
from matplotlib import pylab as plt
# matplotlibのデフォルトフォントをTakaoGothicに設定
font = {'family' : 'TakaoGothic'}
matplotlib.rc('font', **font)
# columnsとtitleに日本語を使ってみる
df = pd.DataFrame( [ [0, 1], [0.5, 1.5] ], columns=(u'甲', u'乙') )
df.plot( title=u'日本語' )
plt.show()
上記はフォントにTakaoGothicを指定している。
subplot
subplotを指定すると、それぞれ別のサブプロットに描画される。
df.plot( subplots=True )
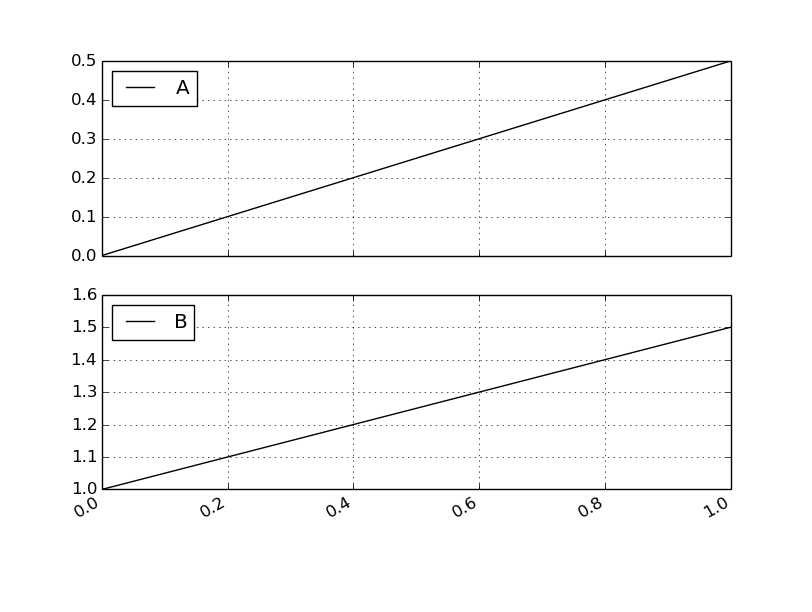
加えてshareyを指定すると、共通のY軸で描画してくれる。
df.plot( subplots=True, sharey=True )
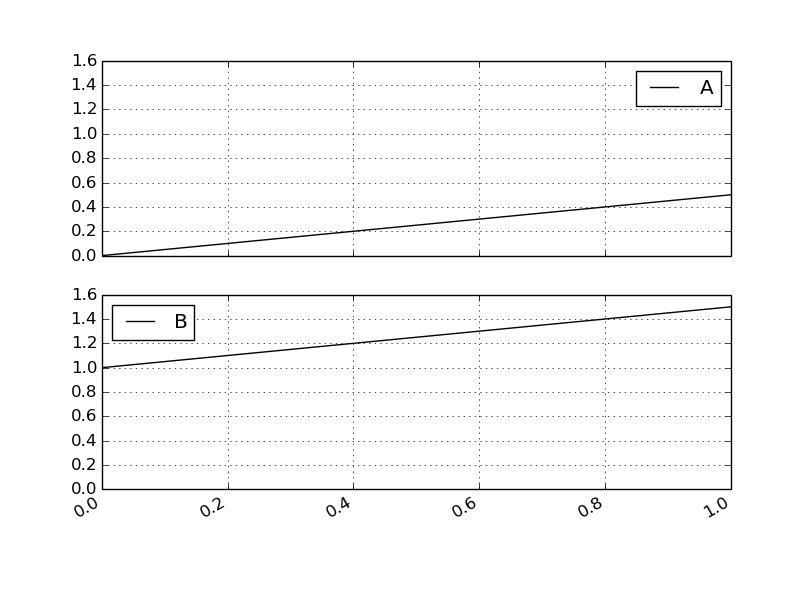
Y軸で見る場合は縦より横に並べた方が良いよね。ということでlayoutで1×2の配置にする。ついでにfigsizeで横長にサイズ調整。
df.plot( subplots=True, sharey=True, layout=(1, 2), figsize=(7, 2) )
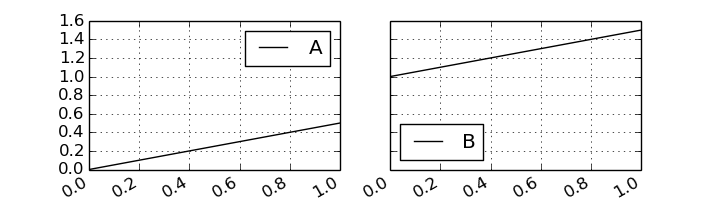
2つのplot間のマージンも消してみる。これはpylabの関数を呼ぶ。
from matplotlib import pylab as plt df.plot( subplots=True, sharey=True, layout=(1, 2), figsize=(7, 2) ) plt.subplots_adjust( wspace=0, hspace=0 )
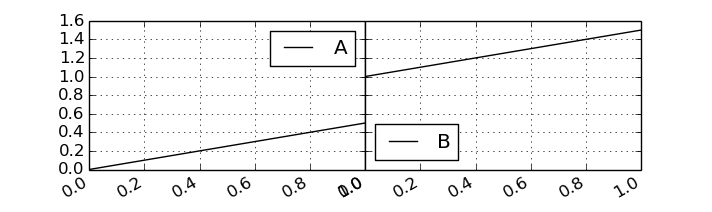
だいぶ見やすくなった。ちょっと左右のラベル被ってるど。
引数にrot=90を入れてラベルを90度回転させれば重ならなく……
df.plot( subplots=True, sharey=True, layout=(1, 2), figsize=(7, 2) ) plt.subplots_adjust( wspace=0, hspace=0 )
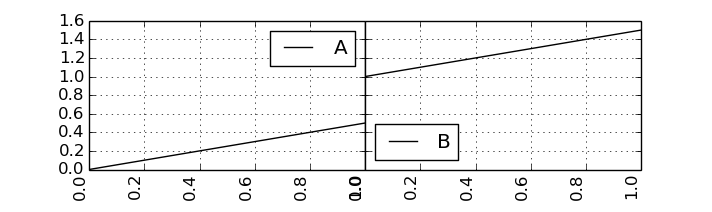
なりませんでした。
kindを指定していろんな種類のグラフを出す
kindにはline, bar, barh, box, kde, area, scatter, hexbin, pie, histが指定できる。デフォルトではline(折れ線グラフ)が描画される。
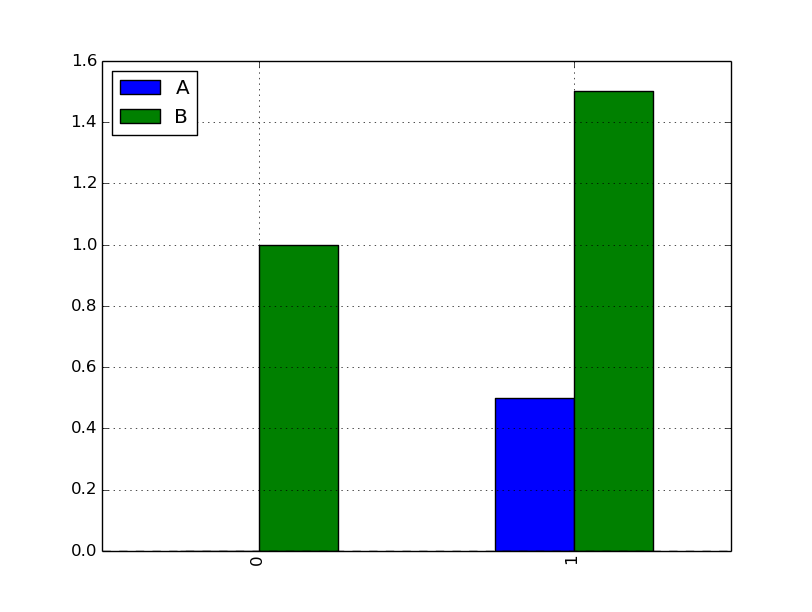
barを使ってみる。
df.plot( kind='bar' )
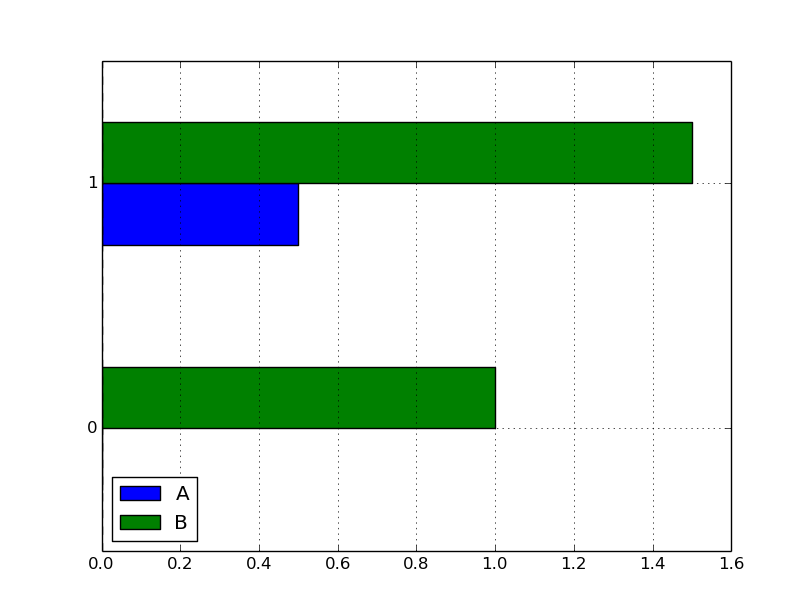
次、barh。
df.plot( kind='barh' )
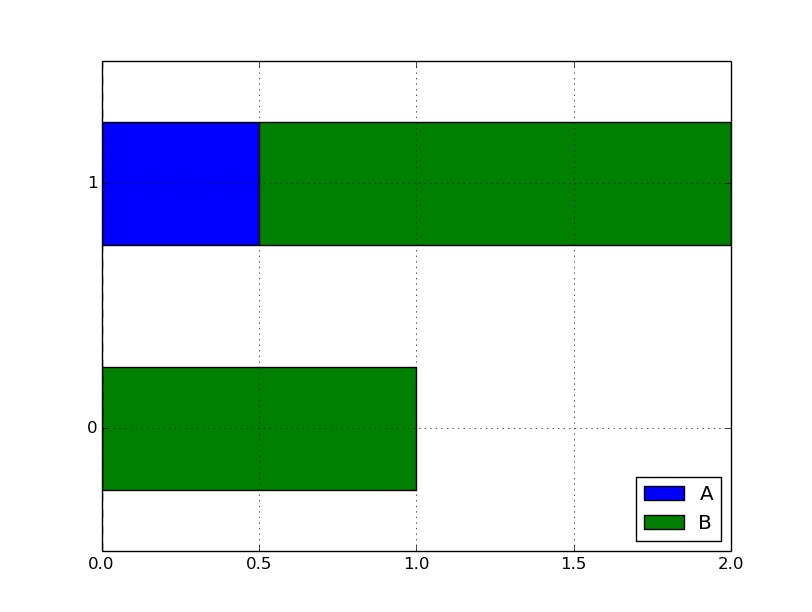
barhでstacked=True。
df.plot( kind='barh', stacked=True )
ちょっとデータが面白くないので、お色直し。
df = pd.DataFrame( np.random.randn(10, 2), columns=('A', 'B') )
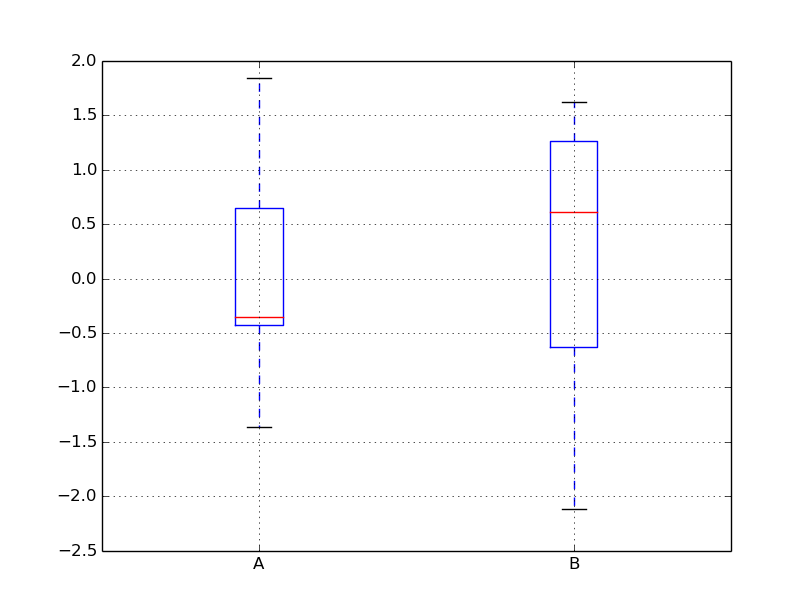
box
df.plot( kind='box' )
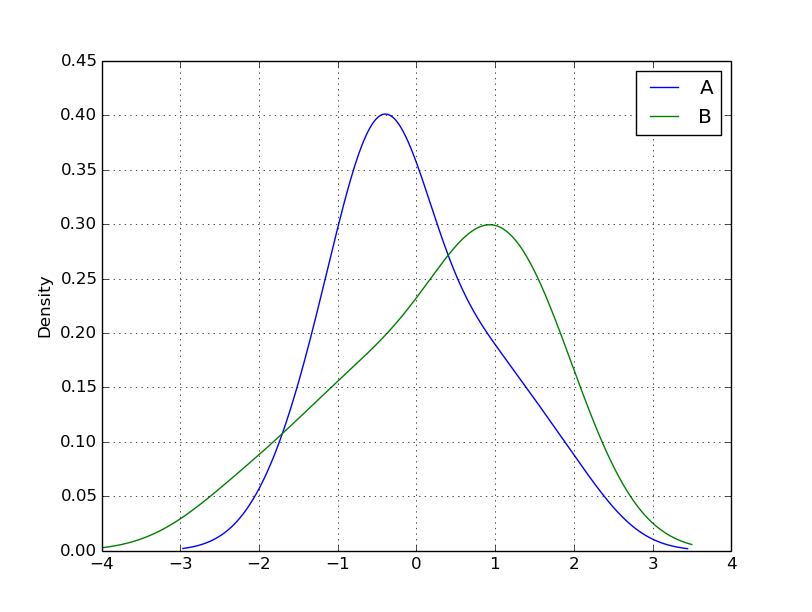
kdeはdensity plots。
df.plot( kind='kde' )
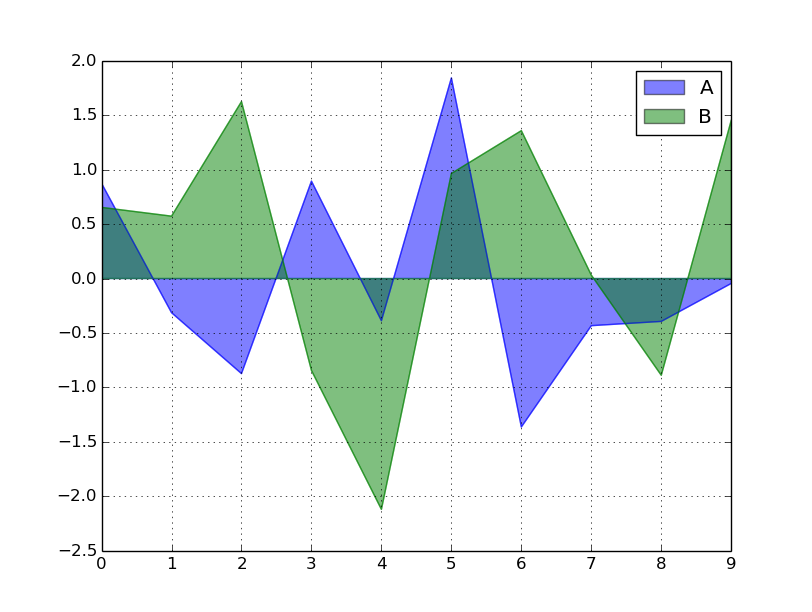
次はarea。all positiveかall negativeでないときはstacked=Falseにしないと出ない。
df.plot( kind='area', stacked=False )
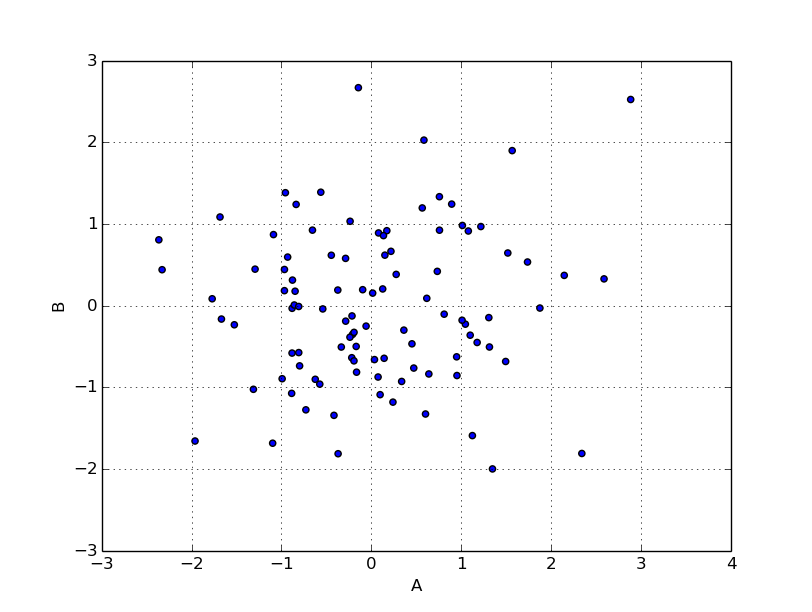
scatter。点が10個だとつまらないので100個に増やす。X軸とY軸、それぞれどのカラムを利用するか指定する必要がある。
df = pd.DataFrame( np.random.randn(100, 2), columns=('A', 'B') )
df.plot( kind='scatter', x='A', y='B' )
hexbin(Hexagon Binning)。要素が1000個でgridsize=20の場合はこんな感じ。
df = pd.DataFrame( np.random.randn(1000, 2), columns=('A', 'B') )
df.plot( kind='hexbin', x='A', y='B', gridsize=20 )
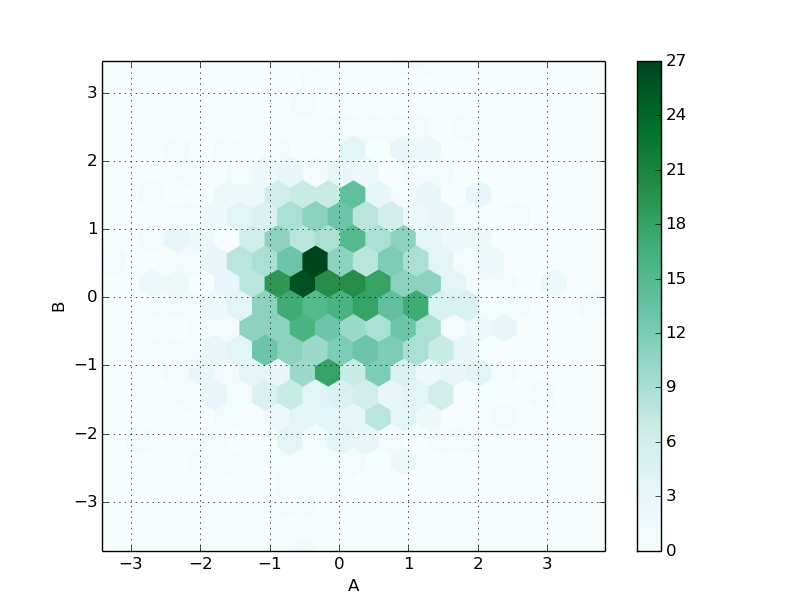
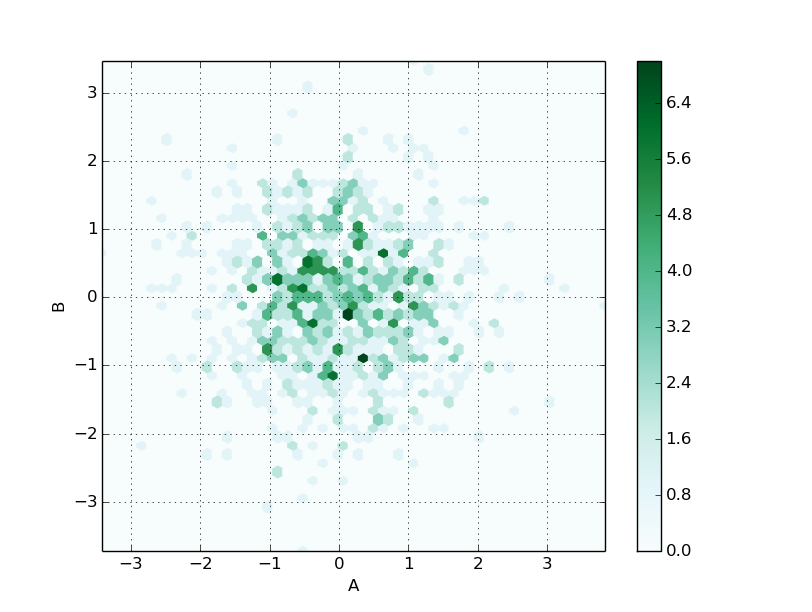
gridsizeを50まで増やすとこんな感じ。
df.plot( kind='hexbin', x='A', y='B', gridsize=50 )
pie
# 要素数は100として
df = pd.DataFrame( np.random.randn(100, 2), columns=('A', 'B') )
# 負の値があると怒られたので適当に正にしてしまって
df['A'] = df.a.apply( np.abs )
# カラムAをpieでplot
df.plot( kind='pie', y = 'A' )
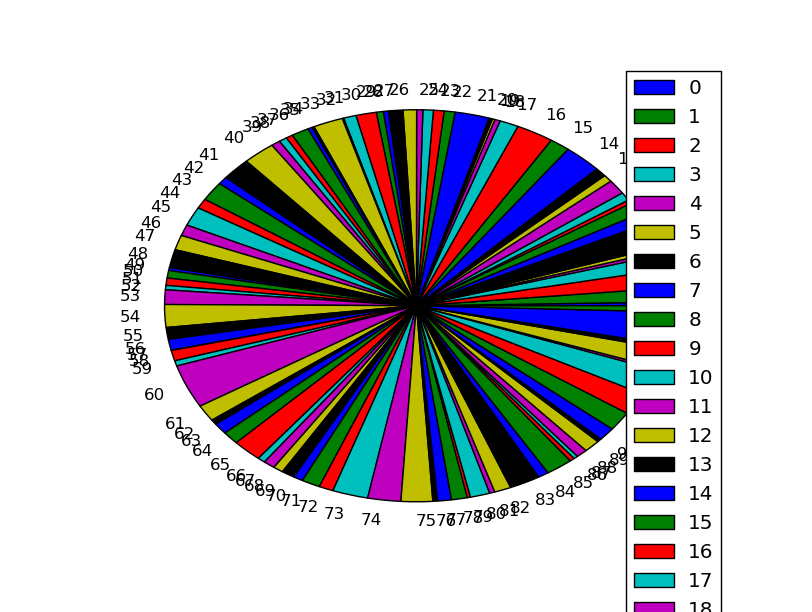
なんかカラフルなことになった。100個もpieチャートで書いてはいけない。
hist。複数カラムだと被るので透明化してみる。
# 適当にズレがあるカラムAとカラムBを作る
df = pd.DataFrame( columns=('A', 'B') )
df.A = np.random.randn( 100 )
df.B = np.random.randn( 100 ) + 1
# alphaを0.3にして、Aを赤、Bを青にしてplot
df.plot( kind='hist', alpha=0.3, color=('r', 'b') )
Aが赤、Bが青、被ってるところが紫。まあ、ヒストグラムをこういう使い方はあまりしないか。
複数のplotをまとめて描画
plotの戻り値としてaxesが返ってくるので、それを指定すればまとめられる。
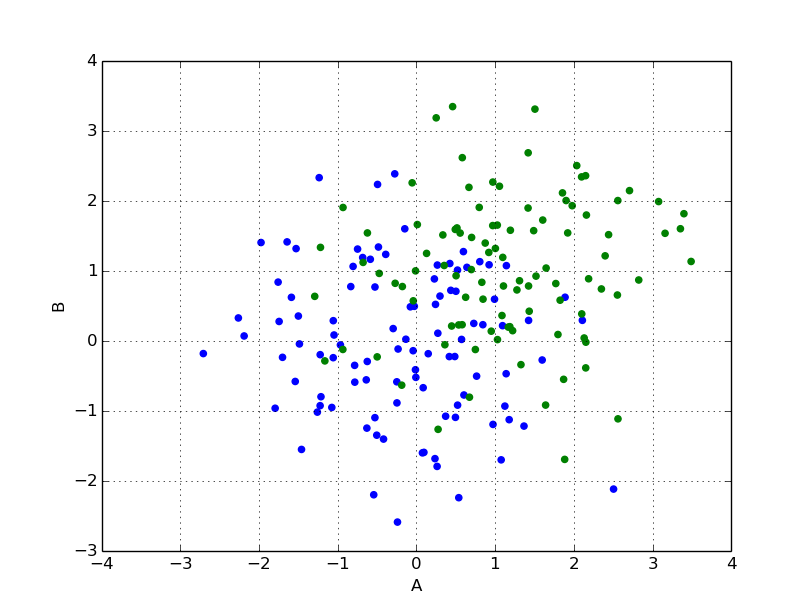
試しに2つのscatterを書いてみる。
# 1つめを青でplot
df1 = pd.DataFrame( np.random.randn(100, 2), columns=('A', 'B') )
ax = df1.plot( kind='scatter', x='A', y='B', color='blue' )
# 2つめを緑でplot(ax指定)
df2 = pd.DataFrame( np.random.randn(100, 2) + 1, columns=('A', 'B') )
df2.plot( kind='scatter', x='A', y='B', color='green', ax = ax )
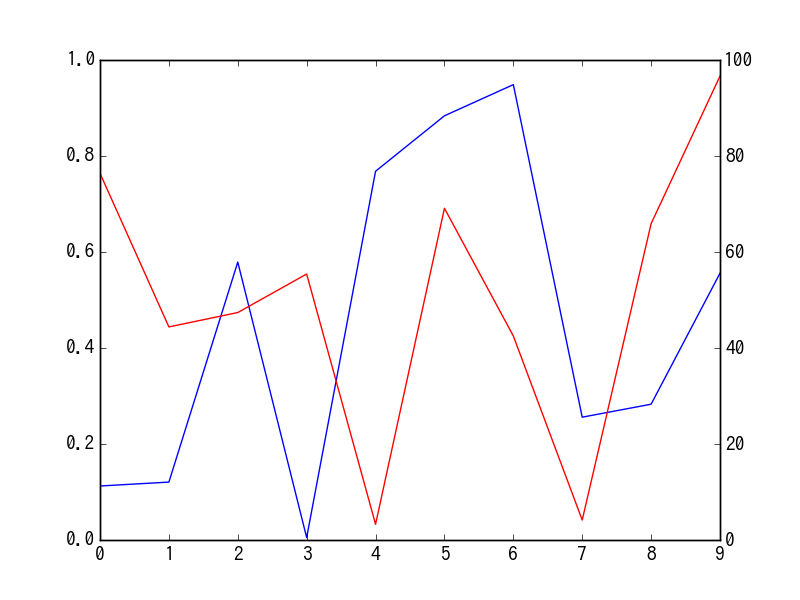
Y軸の数値を2つ持たせる
X軸は共有で、Y軸の片方は0〜1、もう片方は0〜100で分布しているようなスケールに差があるケースで、Y軸の左に0〜1を、右に0〜100を設定してplotする。
とりあえずデータを用意。y1, y2というカラムを持ち、y1は0〜1, y2は0〜100で分布させる。
df = pd.DataFrame( [np.random.random(10), np.random.random(10) * 100] ).T df.columns = ['y1', 'y2']
これでできたのが下記のようなDataFrame。
y1 y2
0 0.112510 76.397826
1 0.120643 44.393145
2 0.578945 47.388112
3 0.005052 55.411362
4 0.768205 3.274651
5 0.883745 69.109424
6 0.948671 42.504412
7 0.255880 4.158040
8 0.282904 65.894865
9 0.555797 96.652777
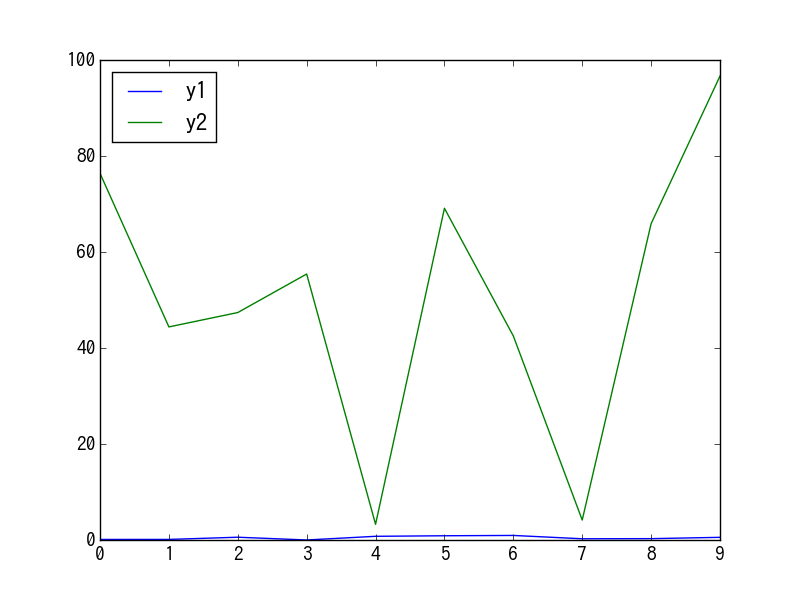
何も考えずにそのままplotさせてみる。
df.plot()
y1の値が小さ過ぎて動きがよく見えない。
これをうまいことplotさせてみる。y1を青、y2を赤で設定する。
ax = df.y1.plot( ylim=(0, 1), color="blue" ) ax2 = ax.twinx() df.y2.plot( ax=ax2, ylim=(0, 100), color="red" )