MapReduceと平均値算出
MapReduceで平均値を出そうとした場合に、Mapper側で計算をしてしまうと結果がズレる場合がある。
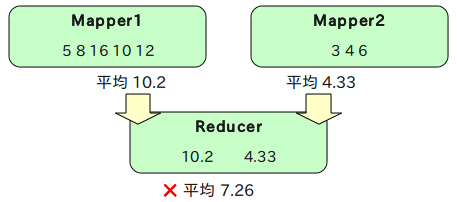
例えば2つのMapperが以下のようなデータを処理したとする。

上記の数値の平均値を計算すると、8になる。
この時、各Mapperがそれぞれ平均値の計算をしてしまうと、Mapper1が10.2、Mapper2が4.33になる。この2つでさらに平均値を取ると7.26になってしまう。
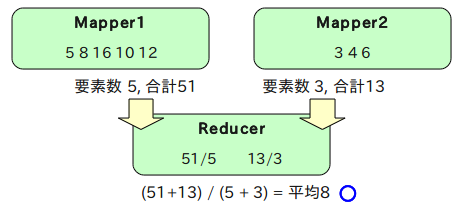
こうした処理を行う場合はReducerに全処理を任せるか、数値のペアを作る。例えばMapperで下記のような「出現数, 合計」のペアを作るようにすれば、Reducerの負担は大きく軽減できる。
サンプルコードの仕様
試しにTwitterに投稿されているメッセージの「時分ごとの文字数の平均」を算出してみる。
もしかしたら文字数が短くなりやすい時間とか、長くなりやすい時間帯とかが見つかるかもしれない。対象データは手元にあった、ストリーミングAPIで取った2011年12月の日本語Tweet、計8,436,431件。ファイルサイズは941MB。
入力データは下記のように「日時(YYYYMMDDHHMMSS)」と「投稿文字列(改行は\nにタブは\tにエスケープされている)」のタブ区切りで保存されているものとする。
20111205083002 おはよー
20111205083005 今日も寒いねぇ
コード例1
同じ型のペアは手近なところだとArrayWritableを使えば一応扱える。
とりあえず下記のようなVLongWritableを格納するArrayWritableを作っておく。VLongWritableは数の大きさによって使用するバイト数が変化する可変長のLong。
class VLongArrayWritable( values: Array[VLongWritable] )
extends ArrayWritable( classOf[VLongWritable], values.asInstanceOf[Array[Writable]] ) {
def this() { this( null ) }
def this( args: Long* ) { this( args.map( l => new VLongWritable( l ) ).toArray ) }
}
あとはこのVLongArrayWritableの0番目の要素にサンプル数を、1番目の要素に文字数の合計を入れていき、Reducerで1番目 / 0番目を計算すれば正しく平均値が出るはず。
combinerを使うとこんな流れか。
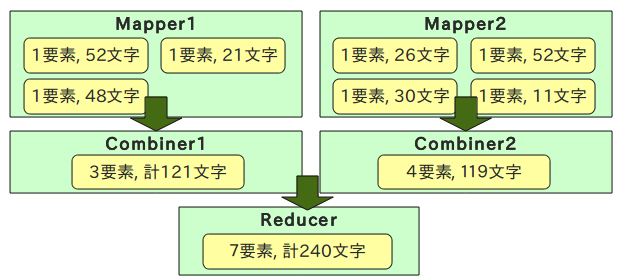
データの内容的にはin-mapper combiningの方が向いているはずなので、今回はそんな感じでコードを書いてみる。
こんな感じのMapperで。
class MyMapper extends SMapper[LongWritable, Text, Text, VLongArrayWritable] {
// データを一時的に格納しておくmap
var map = collection.mutable.Map[String, ( Int, Long )]()
override def map( key: LongWritable, value: Text, context: Context ) {
// 日付(Joda-Time使用)とテキストの長さ取得
val ( hourMin, len ) = {
val items = value.toString.split( "\t" )
val dt = DateTimeFormat.forPattern( "yyyyMMddHHmmss" ).parseDateTime( items( 3 ) )
( dt.toString( "HHmm" ),
items( 1 ).replaceAll( "\\\\t", "\\t" ).replaceAll( "\\\\n", "\\n" ).size )
}
// 加算
val ( count, lenSum ) = map.getOrElse( hourMin, ( 0, 0L ) )
map += hourMin -> ( count + 1, lenSum + len )
}
override def cleanup( context: Context ) {
val arrayWritable = new VLongArrayWritable()
for ( ( hourMin, ( count, lenSum ) ) <- map ) {
// VLongArrayWritableに詰めて出力
arrayWritable.set( Array( new VLongWritable( count ), new VLongWritable( lenSum ) ) )
context.write( new Text( hourMin ), arrayWritable )
}
}
}
こんな感じのReducer。
class MyReducer extends SReducer[Text, VLongArrayWritable, Text, DoubleWritable] {
override def reduce( key: Text, values: Iterator[VLongArrayWritable], context: Context ) {
var countSum = 0L
var lenSum = 0L
for ( arrayWritable <- values ) {
val array = arrayWritable.get()
countSum += array( 0 ).asInstanceOf[VLongWritable].get()
lenSum += array( 1 ).asInstanceOf[VLongWritable].get()
}
context.write( key, new DoubleWritable( lenSum.toDouble / countSum.toDouble ) )
}
}
※コード内のSMapperとかSReducerは下記のようなContextの定義を自動化した自前のクラス
trait SMapper[KEY_IN, VAL_IN, KEY_OUT, VAL_OUT]
extends Mapper[KEY_IN, VAL_IN, KEY_OUT, VAL_OUT] with ImplicitConversions {
type Context = Mapper[KEY_IN, VAL_IN, KEY_OUT, VAL_OUT]#Context
}
自前のPairクラス
ArrayWritableは1つの型しか扱えないので、複数の型を扱う場合には使えない。それに配列の0個目と1個目に値を入れるというのもあまりかっこよくない。
ので、2つの型を格納できるクラスを自作した方が良いかもしれない。象本(第2版)の105ページにペア格納用Writableのサンプルコードが載っている。
下記はそれを参考に書いたそれっぽい独自Writable。今回はキーで使うわけではないのでComparatorについてはあまり気を使わない。
import java.io._
import org.apache.hadoop.io._
// VLongWritableを2つ持てるクラス
class VLongPair extends PairWritable[VLongWritable, VLongWritable](new VLongWritable(), new VLongWritable()) {
def this(value1: Long, value2: Long) {
this()
first.set(value1)
second.set(value2)
}
}
// いろんなWritableComparableなクラスを2つ持つことができるabstractなクラス
abstract class PairWritable[FIRST <: WritableComparable[_], SECOND <: WritableComparable[_]](
var first: FIRST, var second: SECOND)
extends WritableComparable[PairWritable[FIRST, SECOND]] {
protected val firstCls: Class[FIRST] = first.getClass().asInstanceOf[Class[FIRST]]
protected val secondCls: Class[SECOND] = first.getClass().asInstanceOf[Class[SECOND]]
def get: (FIRST, SECOND) = (first, second)
def set(_value1: FIRST, _value2: SECOND) = { first = _value1; second = _value2 }
override def readFields(in: DataInput) {
first.readFields(in)
second.readFields(in)
}
override def write(out: DataOutput) {
first.write(out)
second.write(out)
}
override def hashCode: Int = first.hashCode * 163 + second.hashCode
override def equals(o: Any): Boolean = {
if (o.isInstanceOf[PairWritable[_, _]]) {
val tp = o.asInstanceOf[PairWritable[_, _]]
first.equals(tp.first) && second.equals(tp.second)
} else false
}
override def toString = first + "\t" + second
override def compareTo(w: PairWritable[FIRST, SECOND]): Int = {
val cmp = first.asInstanceOf[Comparable[FIRST]].compareTo(w.first)
if (cmp != 0) cmp
else second.asInstanceOf[Comparable[SECOND]].compareTo(w.second)
}
}
